显卡推荐
AI炼丹卡推荐 #
更新时间 2024年6月25日16:49:39
本文分为三个篇章,分别是个人消费级、发烧友级和企业级,请根据你的需求往下翻。
个人消费级 #
你的废话太多了,我不想看
好吧。2024年最值得推荐的入门级AI算力卡:RTX 2080TI 22G(¥2600) 或者 Tesla P40 24G(¥1600)。
也可以参考一下下面的表格:
| 类别 | 建议显卡型号 | 特性 |
|---|---|---|
| 10系和更老的显卡 | 不推荐 | 架构问题不支持半精度运算,不推荐上AI |
| 8GB显存AI显卡 | RTX 3070TI V2 | 并非RTX 3070TI |
| 1000多点的预算 | RTX 2060 12G | 适合预算在1000多点的显卡玩AI |
| 2000多点的预算 | 魔改的 RTX 2080TI 22G | 性价比拉满AI,魔改的RTX 2080TI 22G不到3000,需要非涡轮卡的版本 |
| 3000多点的预算 | RTX 3080 12G/RTX 4060TI 16GB | RTX 3080 12G是最高性价比的神卡 |
| 富哥 | RTX 4090骇客/即将发布的RTX 4090TI | RTX 4090TI比RTX 4090强15%以上 |
我是好学生,老师教我!
请往下看。
我该买什么显卡? #
有朋友问,我想测试(玩)大语言/Stable Difussion这些AI模型,应该买神马显卡呢?
答案很简单。从RTX4090开始考虑,买你能够负担的起的最贵的显卡。
好吧,这是一个不太负责的答案。
我来翻译一下你的问题:我想玩大模型,最低得上什么卡呢?
其实,大模型也分三六九等,如果你只是跑最低的一等,4G显存可以玩,爷爷传下来的1050TI也能上。
如果你手头恰好有一张N卡,我是说NVIDIA的显卡,恰好它的显存不小于4G,那么你可以尝试用它跑一跑体量较小的模型。
例如Stable Diffusion 1.5 或者Qwen 1.5(1.8B)这些比较小的模型。
如果它能够满足你尝鲜的需求,那么你就不必再额外破费购置显卡了。
到底是哪些显卡呢? #
好吧,你喜欢看列表,下面这些显卡都是可以用的:
- RTX 4090(24 GB)
- RTX 4080(16 GB)
- RTX 4070 TI(12 GB)
- RTX 3090 TI(24 GB)
- RTX 3090(24 GB)
- RTX 3080(10 GB)
- RTX 3080 TI(12 GB)
- RTX 6000(24 GB)
- RTX 8000(48 GB)
- RTX 2080 TI(11 GB)
- RTX 3070 TI(8 GB)
- RTX 2080 Super(8 GB)
- GTX 1080 TI(11 GB)
- RTX 2060 Super(8 GB)
- RTX 2070(8 GB)
- RTX 2070 Super(8 GB)
- RTX 2080(8 GB)
- RTX 3060 TI(8 GB)
- RTX 3070(8 GB)
- GTX 1080(8 GB)
- RTX 3060(12 GB)
- RTX 3050(8 GB)
- GTX 1070(8 GB)
- GTX 1070 TI(8 GB)
- GTX 1060(6 GB)
还有可怜的
- GTX 1050TI (4 GB)
找找看,你那落满灰尘的机箱里,有没有上面的某张显卡呢?
什么显卡性价比最高 #
很可惜,你一张上面的卡也没有。
那么,这时候,你就会问,我想买个性价比最高的。少花钱,多办事。
这是一个美好而又朴素的愿望。但是,很不现实。
少花钱,明显不能多办事。
这时候,你又问,我可以不在乎买二手卡,也可以不在乎速度,能跑起来就成!
好吧,你有点上道了。少花钱,不能多办事。但是可以专注办好其中一件事。那么我的建议就是:
显存!显存!显存!
因此,我只推荐两张卡:RTX 2080TI 22G 或者 Tesla P40 24G
RTX 2080TI 22G 是一张魔改卡,官方版本只出到了11G显存,后期通过修改BIOS和加焊芯片实现了22G显存。市价大约在2700左右。
Tesla P40 24G 是一张数据中心专用的计算卡,没有显示器接口,没有风扇,需要走核显或者亮机卡(低性能、便宜、带显示接口的显卡)才能实现显示信号输出。如果你用的是服务器,有相应的散热风道,那么插上就能用。如果你的是普通家用PC,还需要额外购买3D打印的散热风扇组件。这张卡的价格大约在1700左右,散热组件的价格大约70。
其他的卡就不推荐了。
笔记本怎么选? #
这时候,你又问,如果我买笔记本,阁下又如何应对?
嗨,笔记本就别玩了呗。
这是玩笑。你如果考虑笔记本的话,ROG、外星人也有搭配4080显卡的本子,但是我想,如果你买的起,也不会纠结得到处看评测了。
实际上我的3050TI(4G)游戏本也是可以跑Stable Diffusion和LLM的。这种配置的二手游戏本大概3500左右可以买到。新本子的话,至少考虑4060以上显卡。七彩虹的一款4070游戏本价格也打到了6500左右,用来玩一下绘图、推理都没有大问题。
笔记本做模型微调?还是别做白日梦了。
得寸进尺的问题 #
这时候,你又问,大佬,捡垃圾怎么捡?
这里就没什么好推荐的了。P4 8G(600左右),M40 24G(800左右),1080TI 8G(1000左右),勉强能用吧。
技术发烧友 #
我比较喜欢技术发烧友,因为我就是其中之一😏
对于技术发烧友来说,他们的预算更高,同样,对于计算卡的性能要求也更高一些。实际上发烧友和普通个人用户的需求是类似的:花更少的钱办更多的事。只不过他们愿意投入的资金和精力更多。
我建议技术发烧友的首选考虑是2080TI 22G版本,然后是3080 20G版本,以及3090 24G版本和 4090D/4090 24G版本。
24G的显存,可以比较流畅的运行int4格式、参数在32B以下的大语言模型。32B是一个很好的分水岭,从这个量级开始的llm模型,基本上可以满足我们的日常应用。如果有条件上双卡的话,就可以跑72b左右的模型以及进行24B规模以下的LORA微调。
下面是这三张卡的详细信息:
NVIDIA GeForce RTX 2080 TI:
- CUDA 核心:4352
- 显存:11GB GDDR6(22GB魔改版本)
- 价格:二手2600~2700
NVIDIA GeForce RTX 3080 TI:
- CUDA 核心:8704
- 显存:10GB GDDR6X(推荐上20GB魔改版本)
- 价格:二手4500左右
NVIDIA GeForce RTX 3090:
- CUDA 核心:10496
- 显存:24GB GDDR6X
- 价格:二手6500左右
NVIDIA GeForce RTX 4090D/4090:
- CUDA 核心:16384
- 显存:24GB GDDR6X
- 价格:14000~16500左右
更多发烧友显卡 #
如果你想要组建多卡平台,那么确实还有很多显卡可以选择。大部分时间,我们主要是进行单线程的推理,希望提高问答的准确度(例如在RAG应用中),并不要求推理速度达到极致。
一般来说,如果推理速度能够满足10 tokens/s,就接近人类对话的反应速度(语速正常或偏慢),按照这个标准,可以选择下面的显卡。
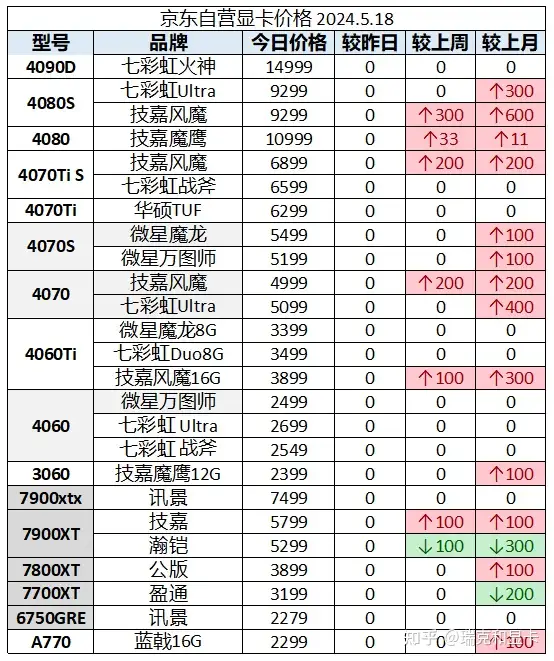
更多显卡的参考价格
下面是2024年第一季度,大显存显卡的参考价格,目前显卡价格的浮动较大。以下价格并未经过仔细核实。
| 型号 | 显存 | 参考价格 |
|---|---|---|
| Tesla M40 无输出 | 24G | 850 |
| Tesla p100 无输出 | 16G | 1050 |
| Tesla P40 无输出 | 24G | 1750 |
| RTX 3090 | 24G | 6300 |
| NVIDIA P6000 | 24G | 5800 |
| 3090TI | 24G | 7900 |
| NVIDIA RTX 6000 | 24G | 15900 |
| NVIDIA RTX A5000 | 24G | 13000 |
| NVIDIA A10 | 24G | 23000 |
| NVIDIA RTX 4090 | 24G | 15200 |
友情提示:M40真的很慢,像跟老奶奶对话一样。
发烧友的主机 #
对于发烧友的需求,你有推荐的主板或者主机吗?
当然咯。帮人帮到底,这里给大家推荐几款用来组建专用主机的配置。
家用机性价比配置 #
既然叫家用,那么兼顾家庭办公、娱乐和游戏,用来跑跑LLM或者SD是附庸功能,因此CPU和接口配置都不能太弱。
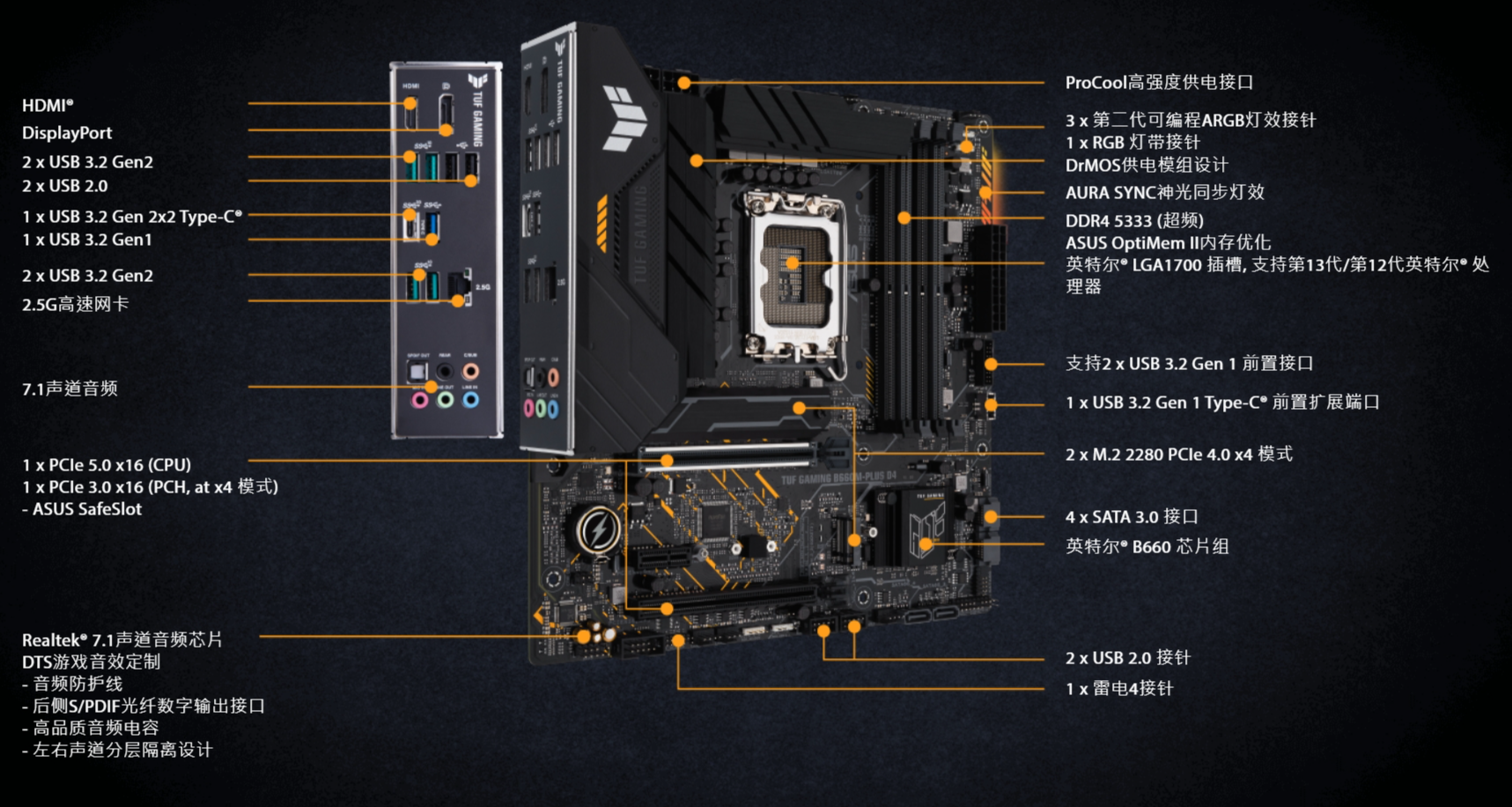
华硕的游戏主板TUF GAMING(电竞特工)系列,包括 B660M-PLUS、B760M-PLUS都带有两根PCIE 3.0/4.0/5.0 x 16的显卡插槽,只要电源够用的情况下,上双显卡进行LLM推理或微调都是没有问题的。
UP在用的是该系列的B460M-PRO(Intel 10代平台),支持两张PCIE 3.0 x 16显卡,跑两张P40、3080 20G、3090 24G问题都不大。
目前适合家用整机配置是:
- B760M-PLUS(Intel 13/14代) + 2 x 4060ti 16G 价格约 1w2
- B760M-PLUS(Intel 13/14代) + 1 x 3090 24G 价格约 1w2
- B760M-PLUS(Intel 13/14代) + 1 x 4090 24G 价格约 2w
以上价格,对于普通家庭用户来说都不算低,主要是为了兼顾娱乐性和LLM的运行,采用了比较新的平台。
服务器性价比配置 #
对于很多发烧友来说,更倾向于组建一台独立的、双卡或者多卡系统用来运行大模型,这个时候就可以考虑退役的二手服务器了。

二手服务器整机推荐
目前适合发烧友的整机配置是:超微7048GR + 4 x 2080ti 22G
整套落地价格可以控制在16000以内。
超微(SuperMicro)是台湾人在美国做的企业,所有又叫美超微。最近股价也是跟着英伟达疯涨。它的产品有很多马甲,比如曙光、浪潮,都是给国内厂商做的代工。所以你看到很多服务器贴的不是超微,但是又写的超微7048、7049等型号,放心,都是超微产的。
4卡魔改2080Ti提供88GB显存可以用来跑Int8的Qwen 72B模型,完全满足日常和简单的团队/企业应用。
- 以Qwen1.5/2 72B模型为例,它的中文处理能力基本可与GPT4相媲美。
- 推荐使用魔改2080Ti的原因:
- 4卡魔改2080Ti提供88GB显存,能处理15k上下文或达到28T/s的速度;
- 8卡魔改2080Ti提供174GB显存,在vllm框架下,Qwen1.5 72B能处理30k上下文或达到35T/s的速度。
- 显卡型号选择:
- 若用于服务器,建议选择涡轮散热加底部供电的版本,这样可以更好地考虑散热和机箱空间的问题。选择信誉良好的商家,优先选择提供一年店铺保障和品牌魔改卡,如华硕。
- 关于推理底座选择:
- 4卡推荐超微7048GR;
- 8卡推荐超微4028GR。
这些服务器主板支持IPMI,可实现远程开关和操控服务器。2080Ti使用PCIe3.0接口,因此选择支持PCIe3.0的主板即可。根据推理模型的内存需求,推荐使用128GB内存。 购买主机时需注意确保配件和设置的兼容性,例如显卡电源线、服务器输出、IPMI密码等,避免购买问题或不兼容的设备。
超微SYS-4028GR-TR和超微SYS-7048GR-TR服务器对比
| 服务器型号 | 处理器 | 最大内存支持 | 存储支持 | 最大卡槽数 | 参考价格 |
|---|---|---|---|---|---|
| 美超微SYS-4028GR-TR | 双路CPU | 最高支持3TB内存 | 支持多种存储 | 8个PCI-E 3.0 x16插槽 | 准系统2200,整备3500 |
| 超微SYS-7048GR-TR | 2个CPU插槽 | 最高支持2TB内存 | 支持多种存储 | 4个PCI-E 3.0 x16插槽 | 准系统5000,整备7000 |
SYS-4028GR-TR和SYS-7048GR都是2020年前后上架的服务器,三年折旧之期已满,目前在二手市场上比较容易淘到。
其中四卡平台7048GR还有7047GR(E3平台,整备大约2000以内)、7049GR(金牌平台,整备大约8000左右)俩兄弟。7047适合囊中羞涩的朋友,至于7049不是特别推荐,性价比较低。
企业应用级 #
老板们,老板们,欢迎看这里!企业这边的预算会相对高一些,另外对于并发、参数量都会有一定的要求。因此,一般都是组件多卡(基本上就是8卡啦)系统,或者服务器集群。
专业消费级显卡和企业级显卡列表
下面是2024年第一季度,企业级显卡的参考价格,目前显卡价格的浮动较大。以下价格并未经过仔细核实。
| 型号 | 显存 | 参考价格 |
|---|---|---|
| Nvidia Quadro P5000 | 16G | 3200 |
| Nvidia Quadro A4000 | 16G | 5150 |
| Nvidia Quadro RTX5000 | 16G | 5000 |
| RTX 2080TI | 22G | 3775 |
| TITAN RTX | 24G | 5800 |
| RTX 3090 | 24G | 6300 |
| NVIDIA P6000 | 24G | 5800 |
| 3090TI | 24G | 7900 |
| NVIDIA RTX 6000 | 24G | 15900 |
| NVIDIA RTX A5000 | 24G | 13000 |
| NVIDIA A10 | 24G | 23000 |
| NVIDIA RTX 4090 | 24G | 15200 |
| L4 | 24G | 16999 |
| NVIDIA A30 | 24G | 41000 |
| Tesla VI00 | 32G | 3550 |
| NVIDIA A100 | 40G | 36900 |
| NVIDIA RTX 8000 | 48G | 19800 |
| Tesla A40 | 48G | 45500 |
| NVIDIA RTX A6000 | 48G | 37000 |
| NVIDIA L40 | 48G | 71000 |
| NVIDIA A16 | 64G | 25000 |
| NVIDIA A100 SXM | 80G | 153000 |
| NVIDIA A100 PCIE | 80G | 850000 |
| H100 SXM | 80G | 310000 |
| H100 PCIE | 80G | 315000 |
AI应用场景推荐的显卡
当然啦,钱要花在刀刃上,公司的钱也不是大风刮来的,不能屁股决定脑袋,而是先要看应用的需求,然后再来购置相应的硬件。
对于企业来说,推理(就是让大模型回答问题)应用的场景会远高于微调(就是调教私有大模型)应用的场景。
通常,我们希望在企业会部署这样一些服务:智能体平台(自动化任务执行)、RAG 本地知识平台、AI搜索平台。这些平台对于LLM的需求是多大呢?
对于商用来说,至少需要72B以上的模型。
但是72B、110B甚至26B的模型,有着不同的运行方式,包括FP32、FP16、Int8或者Int4等等,它们的性能和效率各有不同,对于内存和GPU的算力要求也不一样。
模型量化的具体细节,我们在这里不做深入探讨。原则上,同一规模的模型,采用的运行模式精度越高、效果越好。
因此,我们推荐企业采用Int8及以上的模型来运行实际业务。这种模式的性能损失可以控制在1%以内,显存占用却可以缩减一半(1B~1G)。
显卡与模型规模对照
| 使用场景分类 | 模型大小 | 推荐型号 |
|---|---|---|
| 预训练 | <7B | 3090 (推荐) 4090 (性价比高) V100 32G A100 40G PCIe (推荐) A800/H800等 |
| 和全量微调 | 7B-13B | 3090 4090 A100 40G PCIe(性价比高) A800/H800等 |
| 14B-70B | A100 40G PCIe A800/H800等(性价比高) | |
| >70B | A800/H800/H100等 | |
| 推理 | <34B | INT4量化 单卡 可支持: 3090(推荐) 4090(性价比高) |
| <80B | INT4量化 双卡 可支持: 3090(推荐) 4090(性价比高) | |
| <120B | INT4量化 四卡 可支持: 3090 24G(推荐) 4090 24G(性价比高) | |
| <260B | INT4量化/FP16 多卡(4张以上) A100 80G/A800 80G |
这个表格给出了运行模型所需显卡的一些参考。
研发测试级 #
研发/测试级别的硬件平台,应该计划的采购费用约在10w到20w之间。
这里给大家推荐一款华硕的服务器主机华硕ECS8000 G4 ,单主机价格约2.5万元。具体参数看这里:https://servers.asus.com.cn/products/servers/gpu-servers/ESC8000-G4 。
| 华硕ECS8000 G4 服务器主要参数 | |
|---|---|
| 处理器 | 至强金牌服务器CPU |
| 主板 | Intel C621八卡服务器主板 |
| 电源 | 原装2200W (2+1)冗余服务器电源 |
| 机箱尺寸 | 长798mm* 宽439mm* 高 175mm |
可选的显卡
既然上了华硕ECS8000 G4, 就不要搭配那些拿不上台面的显卡了吧,起码也得是3090起步。至于配几张卡,那就丰俭由人吧。
下面的华硕ECS8000 G4配满8张卡的参考价格:
- NVIDIA RTX 3090 24G 显卡 * 8 整机价格约9万元
- NVIDIA RTX 4090 24G 显卡 * 8 整机价格约16万元
如果相关要压缩费用,或者测试性能需求上线,那首期至少应该配两张3090 24G显卡。后面可以增配,或者换性能更高的4090显卡。
企业应用级 #
老板们,技术是需要投资的!当你的竞争对手正在疯狂囤货H100的时候,不要指望你的队伍用3090干赢别人的飞机大炮!
下面,我们来讨论A100和H100
上硬菜啦!

从这里开始,我们终于可以讨论真正的企业级运算设备!
前面提到的小卡拉米,咱们就不谈了,直接上硬菜:单卡价格约 12w 的 A100 ,单卡价格约 24w 的 H100。
A100的参数
- CUDA核心数量:6912个
- 显存容量:40GB HBM2
- 内存带宽:2TB/s
- TDP(热设计功耗):400W
H100的参数
- CUDA核心数量:12000个
- 显存容量:80GB HBM2e
- 内存带宽:3TB/s
- TDP(热设计功耗):600W
关键是,这些显卡很难单独买到哟~~想买,都是得搭配服务器买套餐来的。
首先是超微(Supermicro)推出搭载 8-GPU 的 8U 服务器 GPU SuperServer SYS-821GE-TNHR。
这是一款AI业务专用的服务器。
CPU
- 双路Intel第三代至强可扩展处理器
- 2*8468(48核心,铂金版,2.1GHz 超频3.8GHz)
GPU
- NVIDIA HGX H100/H800(80G SXM5)
- 支持训练速度比前代GPU快5倍
内存与存储
- 系统内存槽位: 32 DIMM slots
- 最大内存支持: Up to 8TB (32x 256 GB ECC DDR5)
冗余 3000W Titanium Power Supply 支持高性能计算、AI/深度学习训练、工业自动化等应用
具体参数详见:https://www.supermicro.org.cn/zh_cn/products/system/gpu/8u/sys-821ge-tnhr
其次是广受欢迎的戴尔推出的 8-GPU服务器 PowerEdge XE9680。
Dell的PowerEdge XE9680是一款专为人工智能(AI)、机器学习和深度学习设计的高性能应用服务器。尺寸规格为6U。
CPU
- 两块4代Intel® Xeon® Scalable处理器,每块高达56核心
GPU
- NVIDIA HGX H100 80GB 700W SXM5 GPUs,
- 通过NVIDIA NVLink技术完全互连
内存与存储
- 内存模块插槽:32个DDR5 DIMM插槽
- 最大RAM:RDIMM 4 TB max
- 前置硬盘:最多8 x 2.5英寸NVMe/SAS/SATA SSD驱动器,总计最多122.88 TB
- 后置硬盘:最多16 x E3.S NVMe直接驱动器,总计最多122.88 TB
提供2800W Titanium冗余电源,支持200-240 VAC或240 VDC
具体参数详见:https://www.dell.com/en-us/shop/ipovw/poweredge-xe9680
这里给大家提供一下PowerEdge XE9680的参考价格: +8张A100整机大约在160-170万元左右,+8张H100整机价格大约在260-270万元左右。
温馨提示:我这边朋友也有一些渠道,有需求的大老板可以联系我们哟。
关于NvLink(连接器) #

显卡NvLink是一种连接器,可以将两张显卡连在一块,共享显存。
两张3090TI 24G可以通过NvLink连接器连在一起共享显存,两个连一块之后呢,就有48G的显存了。
但是一根NvLink只能连俩显卡,多了不行,而且也不能自动(无脑)整合GPU算力(需要在软件算法层面整合),实际上就是把一张显卡的显存借给另一张用。
但是随着PCIE 5.0的普及,NvLink显得有些多余了。从4090开始,英伟达取消了NvLink接口。
最新的消息是,英伟达会将NvLink技术集成到自研的计算设备中,作为主板的通讯标准。但是呢,老的NvLink技术基本上已经死了。
关于贸易禁运 #
2023年10月17日,美国商务部工业和安全局(BIS)公布新的先进计算芯片、半导体制造设备出口管制规则,限制中国购买和制造高端芯片的能力,并将中国GPU企业及其子公司列入了实体清单。
具体的显卡型号包括:
| TF32算力(TFLOPS) | TF16算力(TFLOPS) | TPP | Die Dize (mm2) | PD=TPP/Die Size | |
|---|---|---|---|---|---|
| A100 | 155.92 | 311.84 | 4989.44 | 826 | 6.04 |
| A800 | 155.92 | 311.84 | 4989.44 | 826 | 6.04 |
| H100 | 756 | 1513 | 24192 | 814 | 29.72 |
| H800 | 756 | 1513 | 24192 | 814 | 29.72 |
| L40S | 183 | 362 | 5856 | 609 | 9.62 |
| RTX4090 | 82.58 | 82.58 | 2642.56 | 609 | 4.34 |
| 资料采源: 算力指标来自英伟达官网和TechPowerUp. |
这一项贸易禁运呢,是由美国商务部单方面实施的。国内并没有任何销售限制,只要能够通过其他的渠道(水货)进入到国内市场,对于购买者来说就没有任何区别了。
实际上,我们发现这些显卡目前在市场上的货源充足。
更多厂商 #
最后,你又问,我的AMD显卡……摩尔线程……Google TPU……
抱歉,AMD的PyTorch好像到现在都没影呢。你还是老老实实拿AMD卡玩游戏去吧。 抱歉,摩尔线程好像有PyTorch了,但是只能Linux跑,效率貌似不高,如果单纯为了做技术测试,你就为科学献身吧。 抱歉,我买不起鲲鹏,鲲鹏不是我等凡夫俗子能玩的,但是鲲鹏已经出了大模型训练、微调和推理的框架,都是企业级的应用,您还是联系华为的技术支持吧。 抱歉,Google我不熟,我只会用Colab。
参考文献 #
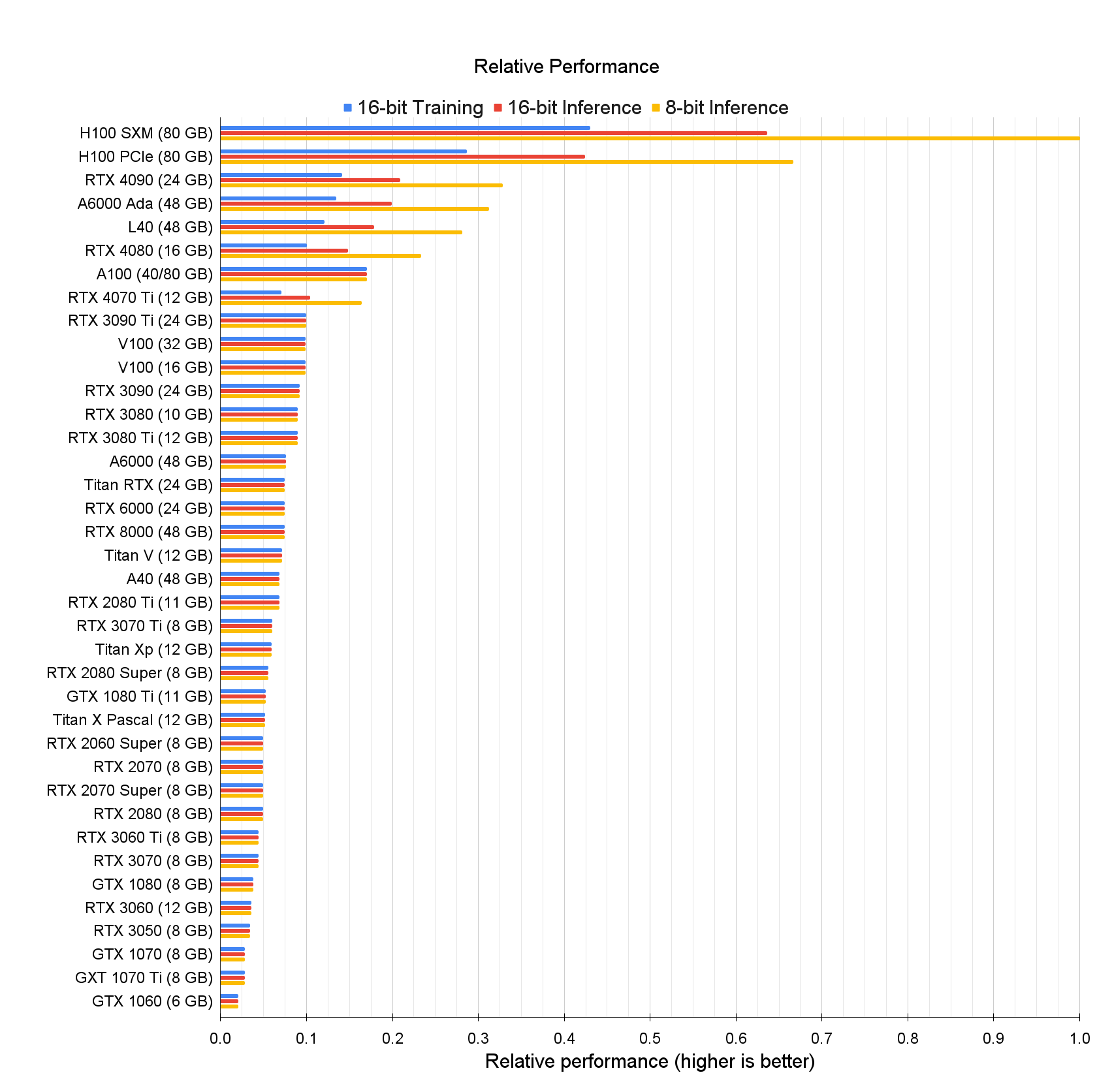
下面是两篇非常专业的GPU评测博文可以参考,但都是2023年的数据,有些后来新发售的显卡不在表中。
Stable Diffusion Benchmarks: 45 Nvidia, AMD, and Intel GPUs Compared #
稳定扩散基准测试:45个Nvidia、AMD和Intel GPU比较 #
Stable Diffusion和其他基于AI的图像生成工具,如Dall-E和Midjourney,是目前深度学习最受欢迎的应用。使用经过训练的网络来创建图像、视频和文本已经不仅仅是一种理论上的可能性,现在已经成为现实。虽然像ChatGPT这样更高级的工具可能需要安装大型服务器和大量硬件进行训练,但运行已经训练好的网络进行推理可以在PC上使用其显卡完成。消费者GPU使用稳定扩散进行AI推理的速度有多快?我们就是来调查这个的。
https://TImdettmers.com/2023/01/30/which-gpu-for-deep-learning/

Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning #
为深度学习选择哪种GPU:我在深度学习中使用GPU的经验和建议 #
深度学习是一个对计算要求很高的领域,您对GPU的选择将从根本上决定您的深度学习体验。但是,如果你想购买一个新的GPU,什么功能是重要的?GPU RAM、核心、张量核心、缓存?如何做一个具有成本效益的选择?本文将深入探讨这些问题,解决常见的误解,给予您如何看待GPU的直观理解,并将为您提供建议,这将帮助您做出适合您的选择。
https://www.tomshardware.com/pc-components/gpus/stable-diffusion-benchmarks