利用AI解读本地WORD和PDF文档 构建自有知识库
本教程带领大家使用 Ollama + Qwen(通义千问大语言模型)+ AnythingLLM 搭建本地知识库,实现手搓 AI+专家系统。
· 5 min read
利用AI解读本地WORD和PDF文档 构建自有知识库 #
更多AIGC教程,访问UP「码钉泥」的B站 https://space.bilibili.com/650927704/
本教程带领大家使用 Ollama + Qwen(通义千问大语言模型)+ AnythingLLM 搭建本地知识库,实现手搓 AI+专家系统。今天给自己安排一位全能知识助手,领导再也不用担心我一问三不知了,升职加薪不是梦!
大语言模型的发展真的是一日千里。在前面的教程中,我为各位观众老爷演示了如何利用清华大学出品的ChatGLM3搭建本地的大语言模型,并通过API实现自动化写作。
随着ChatGLM4改为闭源发布,ChatGLM模型的热度一泻千里。新的大模型不断涌现,新的部署工具也层出不穷。阿里巴巴出品的通义千问迭代到1.5版本,性能基本超越ChatGLM3,成为我们新的选择。
今天,我们就要带领大家使用通义千问和LangChain搭建本地知识库,让电脑变成我们信息小助理。
1 运行环境 #
1.1 安装大语言模型 #
在前面的教程中,我们自己配置了Python环境用来运行ChatGLM模型。现在,我们有了更加方便的工具,可以一条指令运行本地LLM模型,那就是Ollama。
访问Ollama.com下载安装包。Ollama目前支持Linux、Windows和MacOS操作系统。并且支持CPU、NVIDIA GPU和AMD GPU。这意味着,如果你的电脑配有显卡,将会优先使用显卡进行推理(这样速度更快),如果没有显卡,将调用CPU进行推理(即使办公笔记本也可以运行,当然,推理速度会有点慢)。
我们先下载最熟悉的Windows安装包。根据默认设置安装。
安装完成后,打开一个CMD窗口,输入
ollama pull qwen:4b
这将帮你下载通义千问1.5_4B模型。模型的大小约2.3GB,无需魔法上网即可下载。
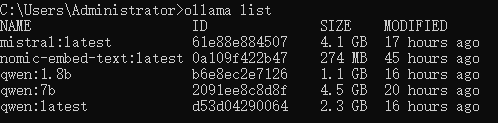
我这边下载了大概20分钟,下载完成后,可以使用Ollama默认的界面运行通义千问1.5_4B模型。
打开一个CMD窗口,输入
ollama run qwen:4b
然后,你就可以在CMD界面提出问题了。输入 /bye 可以退出聊天。

当然,这个界面只能做简单测试,我们后面将接入更加方便的图形界面(包括我们的老朋友Chatbox)进行本地对话。
Ollama支持流行的开源大语言模型,包括llama2和它的众多衍生品(包括vicuna、codellama),以及其他一些热点模型,例如Mistral、Dolphin、Falcon等。
访问https://ollama.com/library可以浏览Ollama提供的所有模型。
1.2 安装向量模型 #
下面我们将需要使用Ollama安装向量模型。向量模型比较小,大约230MB,很快就可以下载好
ollama pull nomic-embed-text
这将会帮助我们下载nomic-embed-text:latest。其中latest表示最新版。
向量模型是用来将Word和PDF文档转化成向量数据库的工具。通过向量模型转换之后,我们的大语言模型就可以更高效得理解文档内容。
向量模型无法单独使用。
1.3 利用Langchain处理文档 #
Langchain是一套利用大语言模型处理向量数据的工具。以前,搭建LLM+Langchain的运行环境比较复杂。现在我们使用AnythingLLM可以非常方便的完成这个过程,因为AnythingLLM已经内置了Langchain组件。
AnythingLLM是一个集成度非常高的大语言模型整合包。它包括了图形化对话界面、内置大语言模型、内置语音识别模型、内置向量模型、内置向量数据库、内置图形分析库。
可惜的是,AnythingLLM目前的易用性和稳定性仍有所欠缺。因此,在本教程中,我们仅使用AnythingLLM的向量数据库和对话界面。LLM模型和向量模型仍然委托给Ollama来管理。
AnythingLLM本身对Ollama的支持也非常完善。只需要通过图形界面,点击几下鼠标,我们就可以轻松完成配置。
第一步,打开AnythingLLM左下角的配置界面
第二步、配置LLM
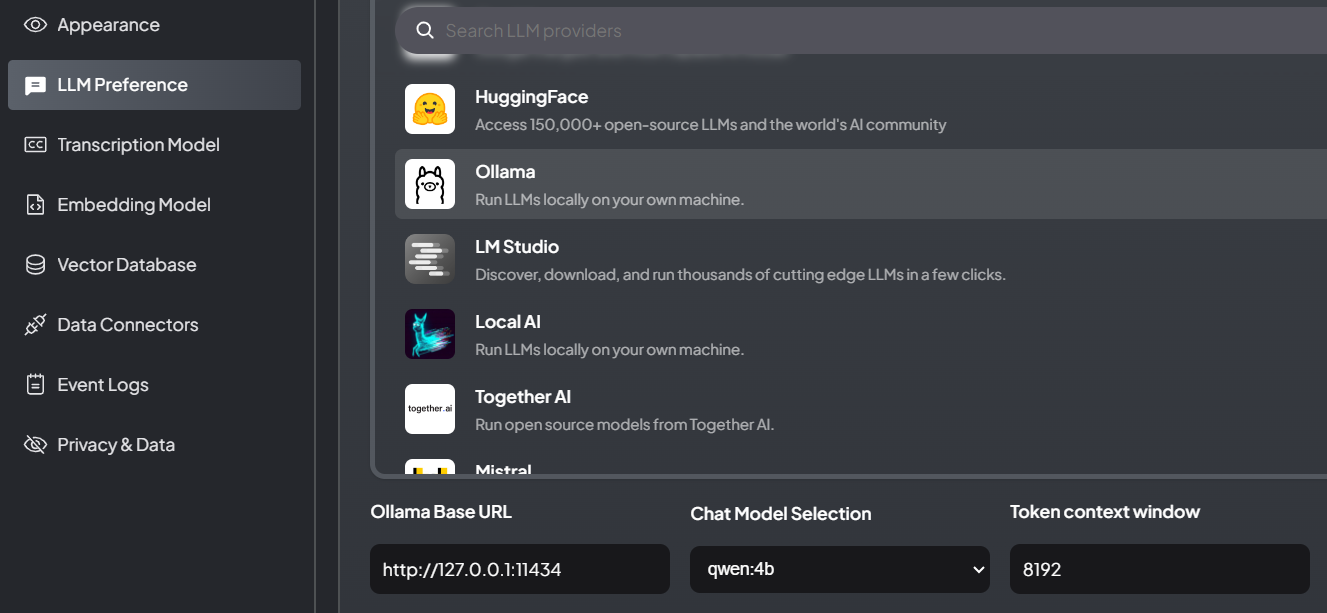
在LLM Preference选项卡中,选择Ollama作为后端。依次填写
URL:http://127.0.0.1:11434/
Chat Model:选择 qwen:4b
Token:8192
点击窗口上方的“Save changes”保存生效。
第三步、配置embedding模型
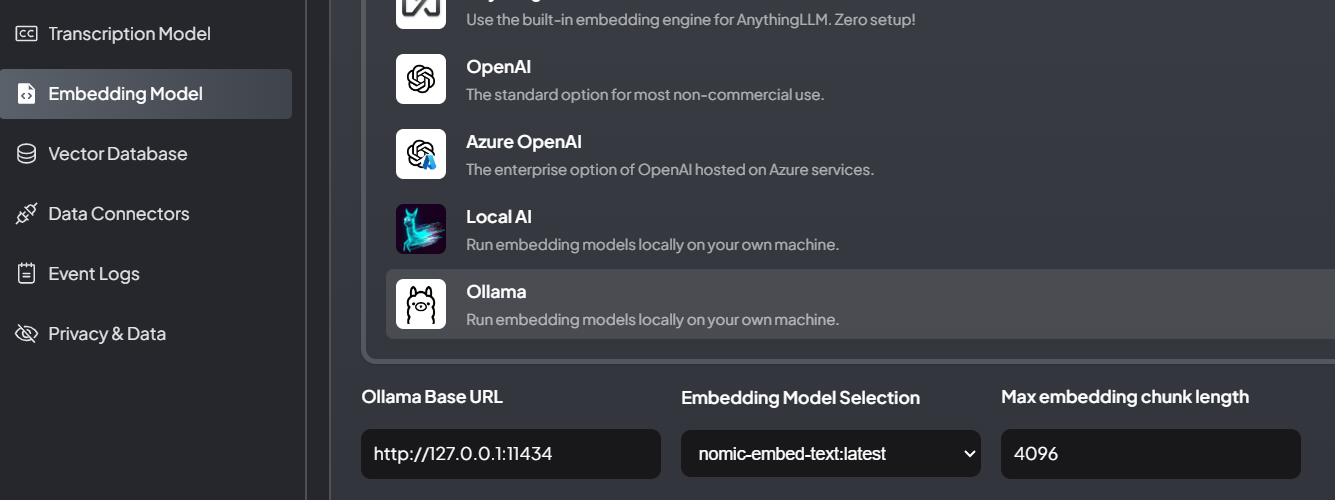
在Embedding Model选项卡中,选择Ollama作为后端。依次填写
URL:http://127.0.0.1:11434
Chat Model:选择 nomic-embed-text:latest
Max embedding chunk length:512
💡 注意:这个Max embedding chunk length数值会影响文档回答的质量,推荐设置成128-512中> 的某个数值。从512往下逐级降低,测试效果。太低也不好,对电脑性能消耗大。
点击窗口上方的“Save changes”保存生效。
第四步、选择LanceDB向量数据库
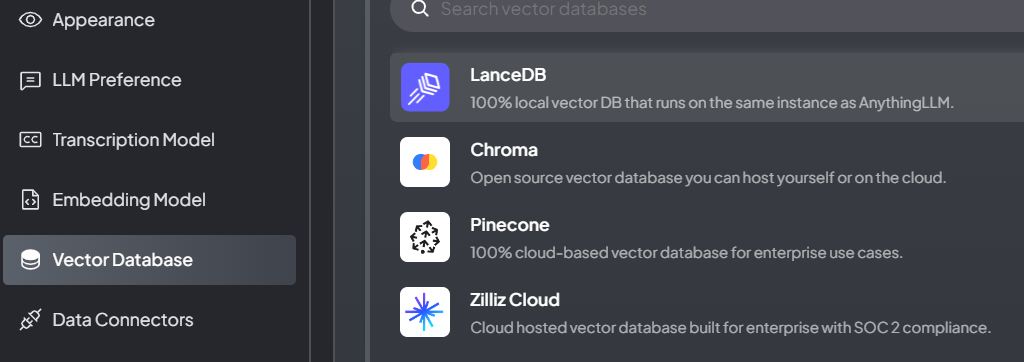
在Vector Database选项卡中,选择LanceDB作为后端。这是一个内置的向量数据库。
如果你熟悉Pinecone等云端数据库,也可以配置相关的数据库,这样可以实现资料库漫游。
2 业务逻辑 #
我们简单介绍一下整个工作流程。
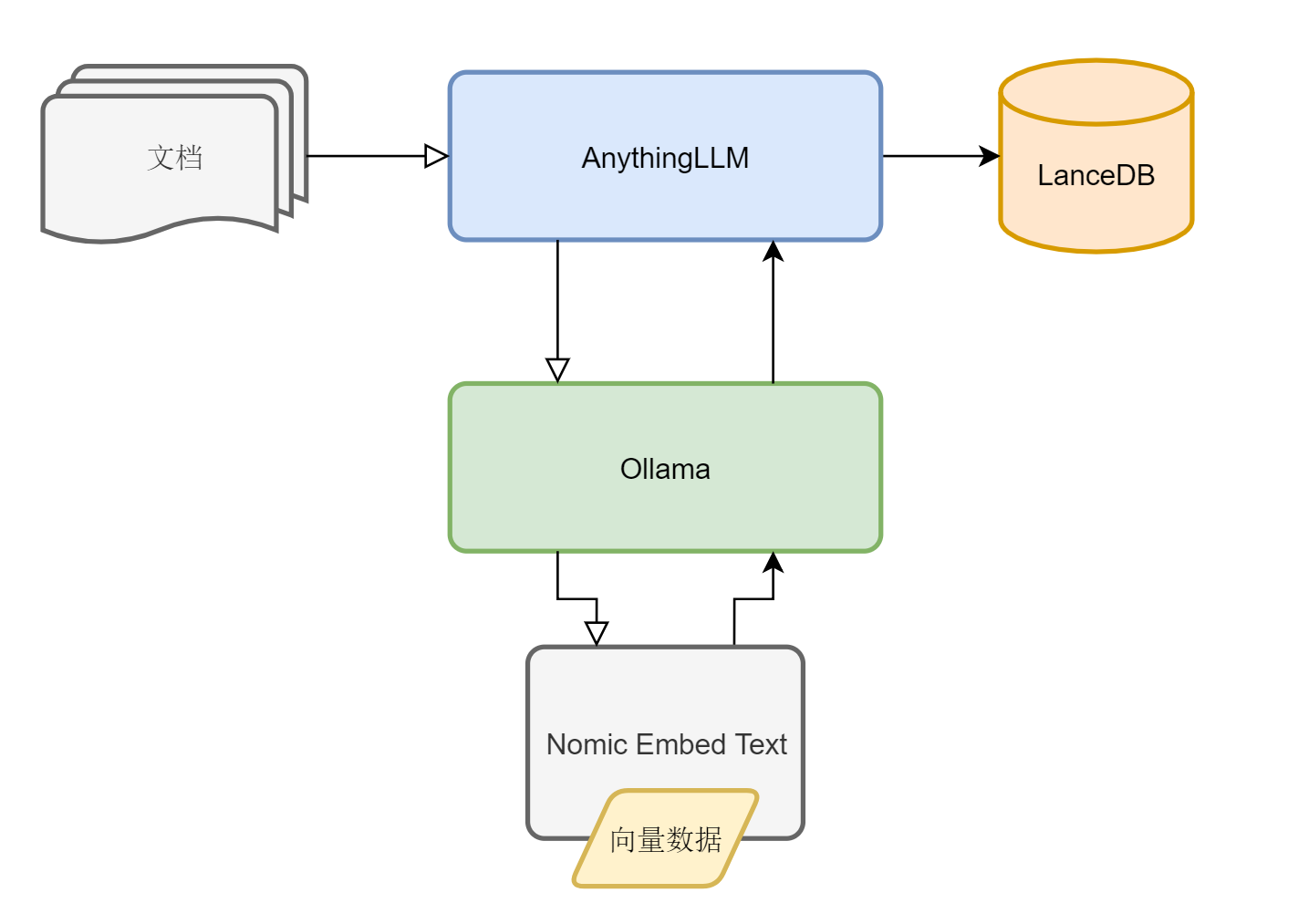
第一步、创建向量数据库
文档→AnythingLLM→Ollama(Nomic Embedding)→向量数据→AnythingLLM(LanceDB)
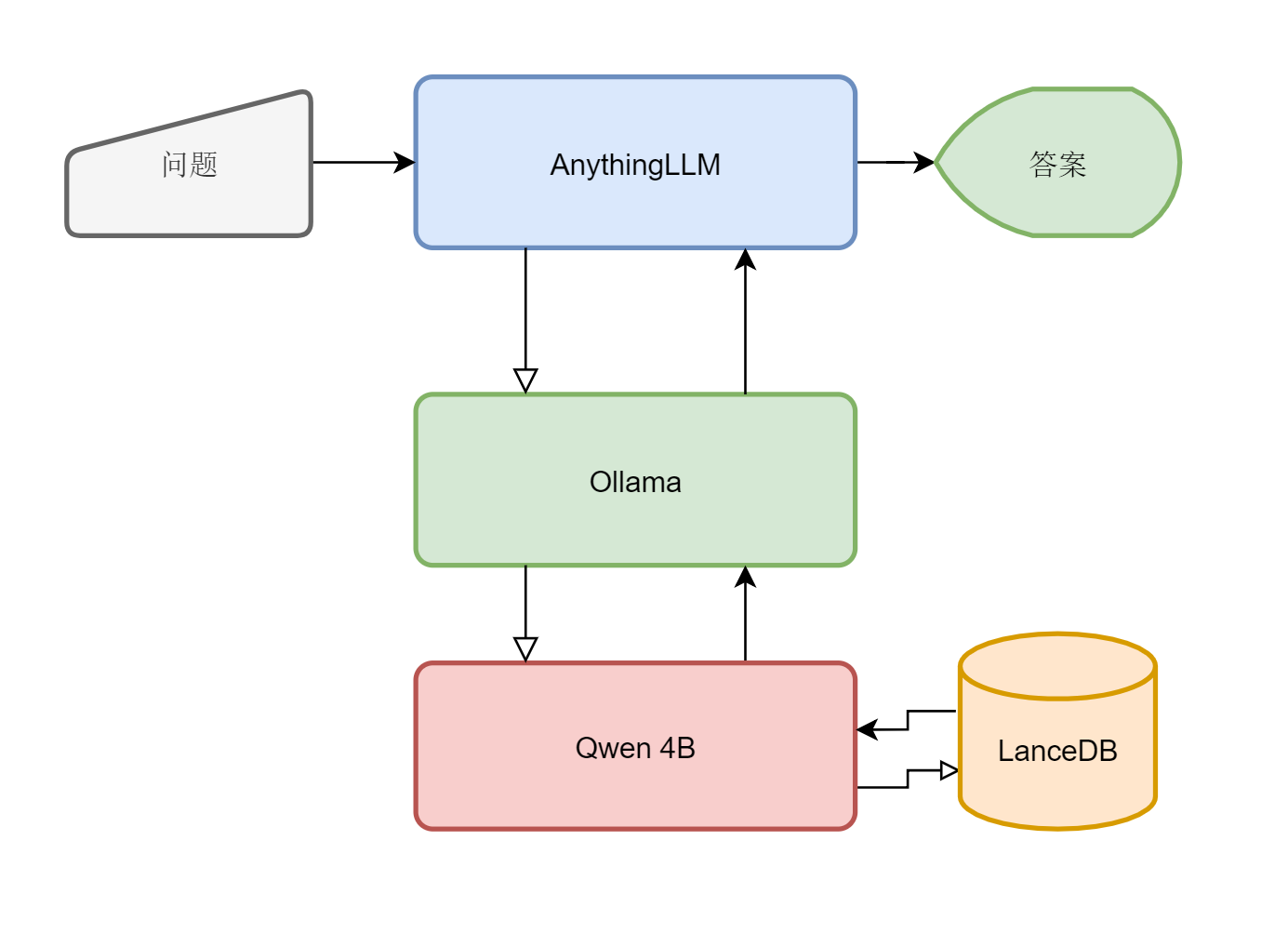
第二步、利用向量数据库回答
问题→AnythingLLM→Ollama(Qwen 4b)→AnythingLLM→答案
3 配置与优化 #
下面,我们开始进入AnythingLLM,配置Workspace以开始基于文档的对话。
点击 New Workspace,创建一个名为Chat的工作空间。无需进行任何设置,就可以直接开始与通义千问进行对话。
再次点击 New Workspace,重新创建一个名为Test的工作空间。我们将在这个空间内上传一些文档。
点击上传图标,拖拽你的资料文档到下面这个大大的按钮上(你也可以单击它!)
AnythingLLM几乎支持所有包含文字的文档格式:txt、doc(word文档)、csv、xls(excel表格)、pdf等等。
我推荐你上传word文档或pdf文档。注意:扫描图片制作的PDF暂时无法支持,你需要使用OCR软件将这种PDF转换成word文档上传。
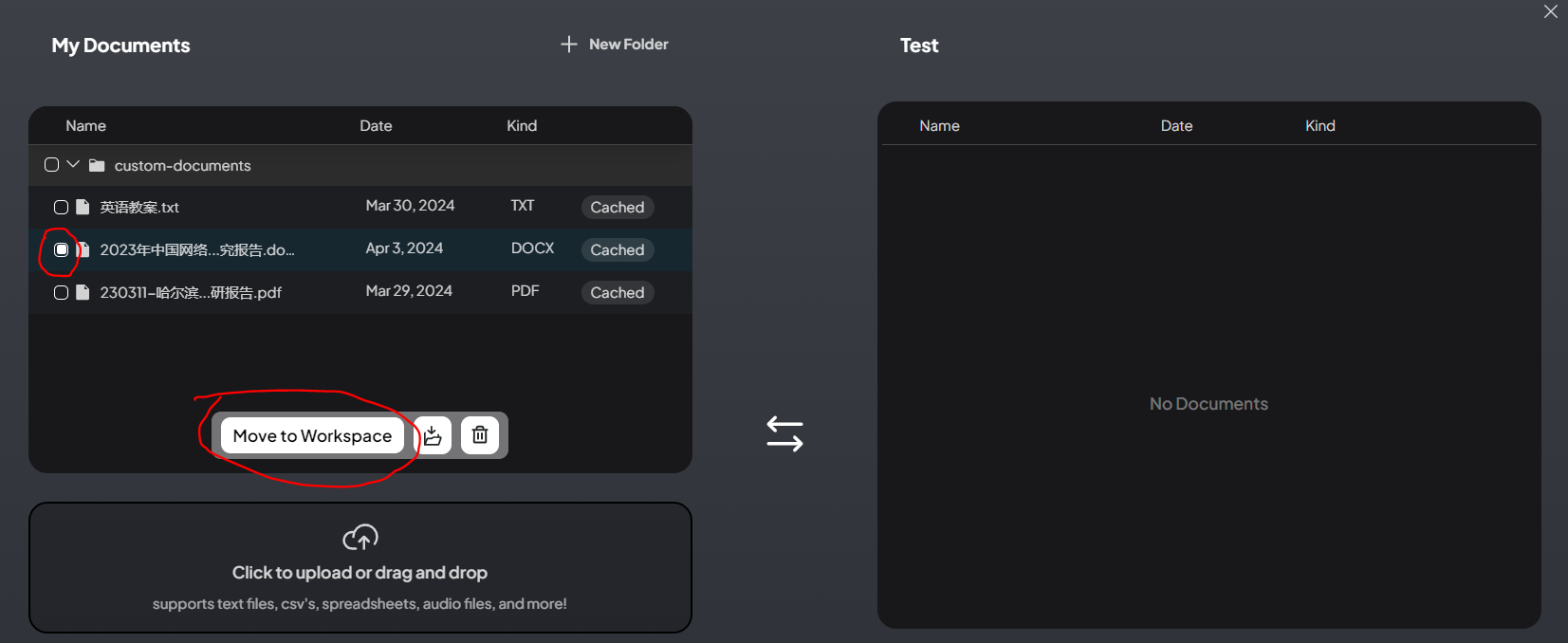
上传完成后,选中相应的文档,并点击 Move to Workspcae。
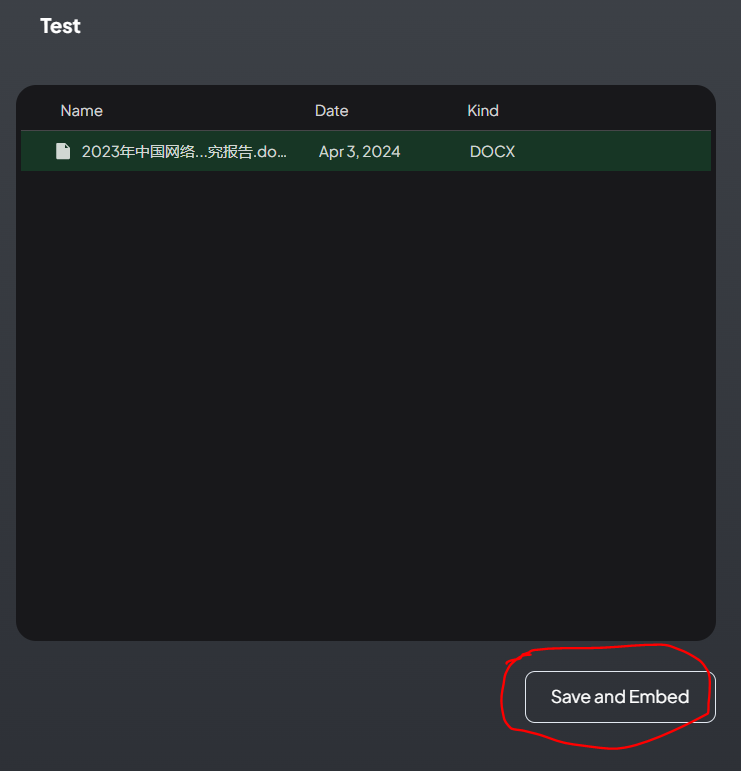
然后点击Save and Embed。
AnythingLLM便开始调用Nomic Embed模型处理你的文件。使用CPU处理一个文件大约需要5~10分钟。我上传的这份《2023中国网络文学产业研究报告》,全文有2万字(去掉了图片),处理了大约七八分钟。完成后,关闭上传窗口。
点击齿轮图标,打开Test空间的设置选项。
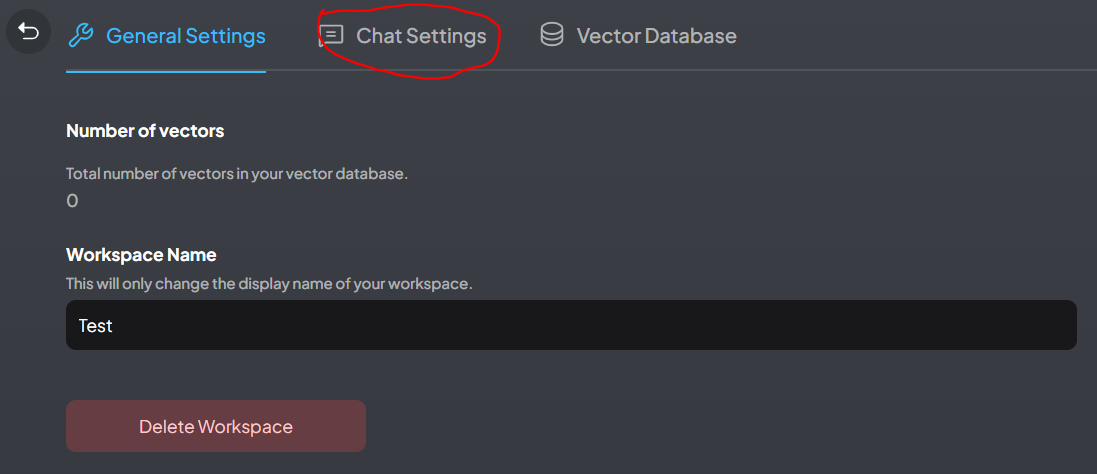
选择Chat Settings,将对话模式更改为Query(默认是Chat)
Query模式能够确保仅采用上传文档中的信息进行回答(而不会采用大模型本身的信息)。
点击Update Workspace,保存设置。点击返回按钮,返回主界面。
下面,是没有开启文档对话(Chat模式、未上传任何文档)的回答效果。明显的泛泛而谈。
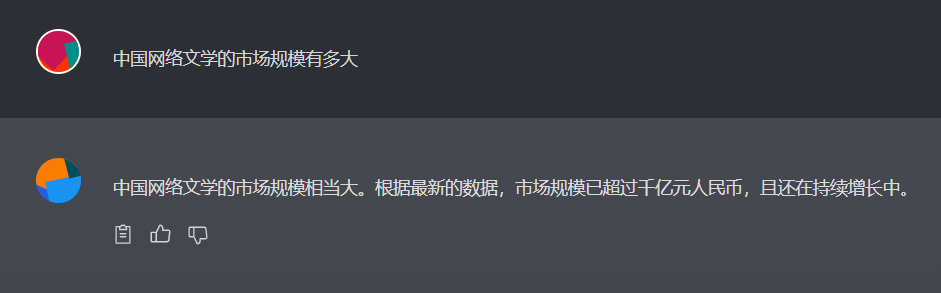
现在我们来试试基于文档对话(Query模式、上传1篇文档)的效果吧。
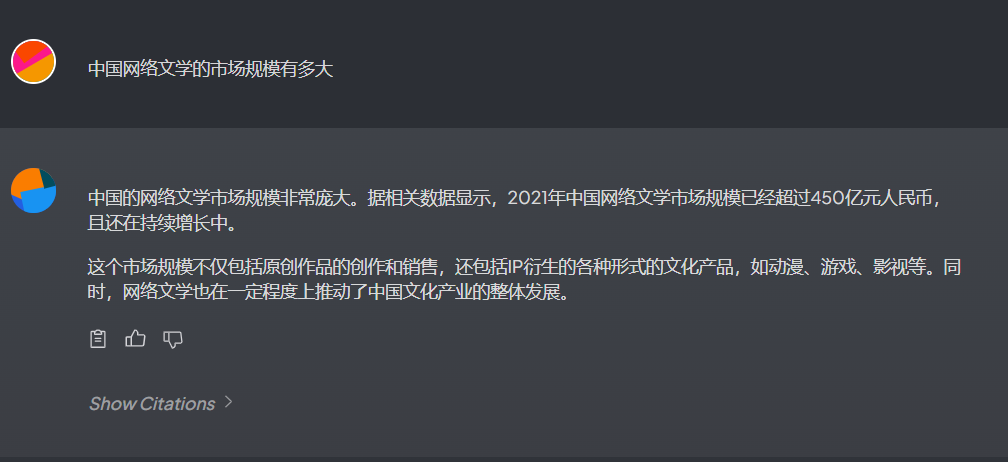
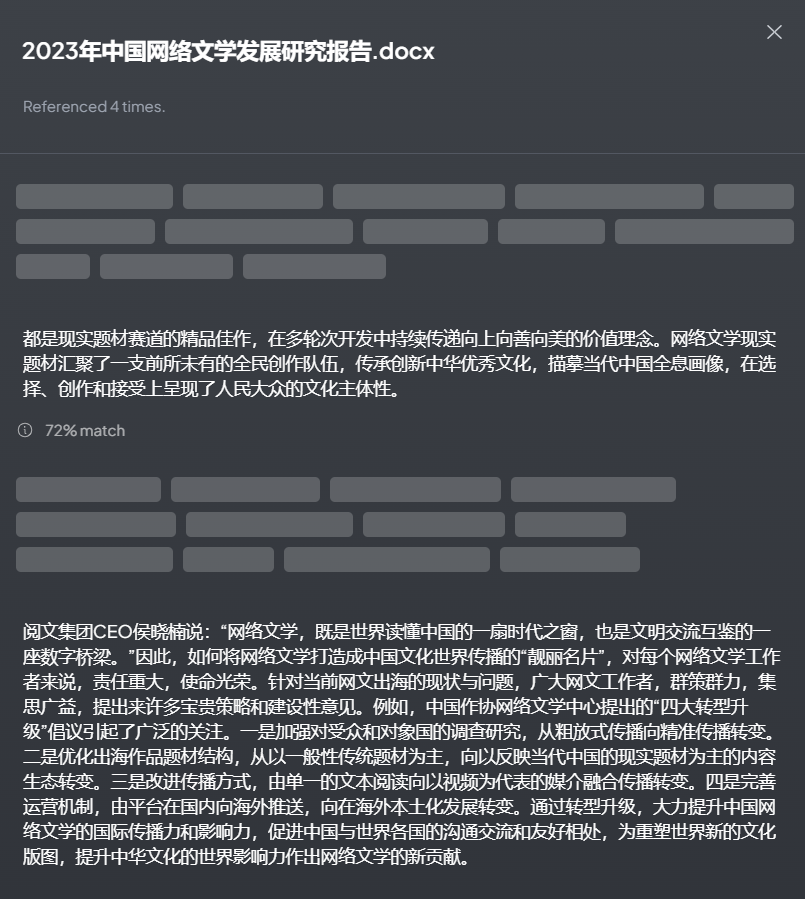
点击Show CItations,可以查看引用的数据。
你可以对一个话题上传多份文档,以提高回答质量。文档的相关性越高,回答的质量更好。如果你对回答不太满意,也可以尝试重新组织一下问题的文字,或者更换体量更大的本地大模型处理。
4 ChatBox集成 #
我们的老朋友ChatBox也可以很容易的集成Ollama。将ChatBox升级到1.2.2以上,即可配置Ollama作为后端,方便的使用通义千问大模型进行聊天了。
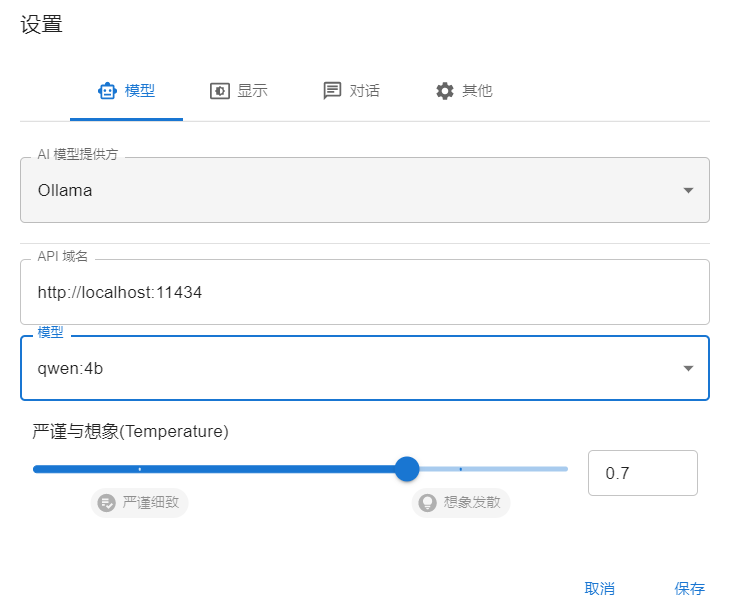
你需要在ChatBox的设置界面中进行选择Ollama作为后端。
在模型选项卡选择 Ollama 作为AI模型提供方。
API域名填写 http://127.0.0.1:11434
模型选择 qwen:4b
保存后即可进行对话。
下面是我使用Ollama运行Mistral 7B进行对话的示例。
ChatBox可以很方便的切换Ollama管理的大语言模型。
5 总结 #
通过今天的教程,我们已经可以不需要进行繁琐的Python环境搭建,就能够方便的在本地运行大语言模型。
Ollama和AnythingLLM方便的将我们需要的大语言模型运行环境,打包成Windows的通用图形界面,降低了大语言模型本地运行的门槛。同时Ollama可以根据我们的硬件配置自动选择使用显卡(GPU)或者CPU来运行量化好的模型。
在我们之前的教程中,只能使用CPU来运行量化后的 ChatGLM3模型。使得拥有GPU显卡的用户运行效率偏慢。Ollama很好的解决了这个问题。Ollama使用16位的GGUF量化模型,相对于之前我们介绍的GGML(Int4)量化模型格式,所保存数据精度更高。
此外,Ollama还支持uncensored llama2模型,可以应用的场景更加广泛。
目前,Ollama对中文模型的支持还相对有限。除了通义千问,Ollama没有其他更多可用的中文大语言模型。鉴于ChatGLM4更改发布模式为闭源,Ollama短期似乎也不会添加对 ChatGLM模型的支持。
尽管有一些不足。但是Ollama和AnythingLLM还是帮助我们更加方便的在本地运行属于自己的大语言模型,使得LLM应用对于普通人来说更加触手可及。
【增补教程】 #
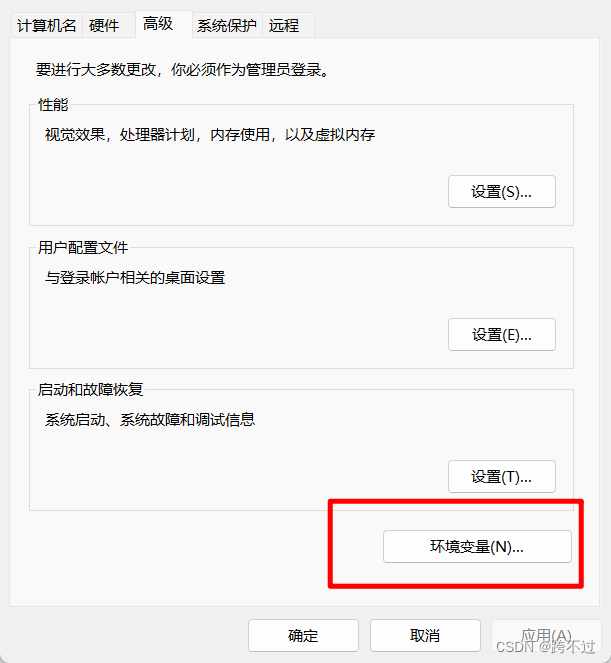
A. 修改本地存储位置 #
Linux、Window都支持更改ollama模型存放位置。因为Ollama默认把模型下载到C盘,但是大家C盘一般都很小,所以可以在安装完成后修噶一下存储位置。
Windows直接进入系统环境变量添加就行
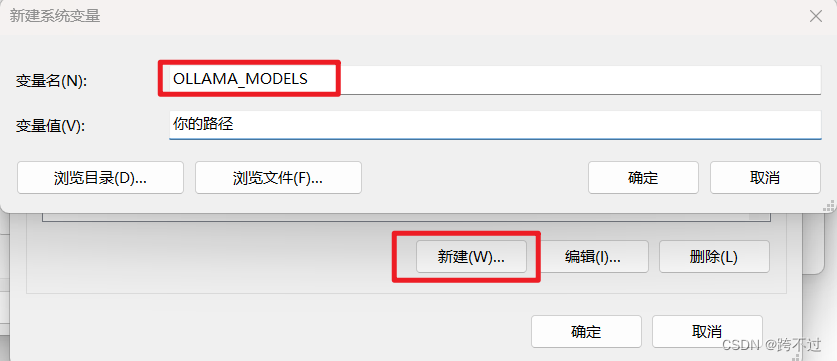
Linux环境下
- 首先第一步:cd /etc/systemd/system/ 打开配置文件vim ollama.service
- 第二步:目录下的environment里面分号隔开添加OLLAMA_MODELS环境变量
- 第三部:source ollama.service
- 最后重启ollama即可

来源:https://blog.csdn.net/weixin_46124467/article/details/136781232
B. 模型推荐 #
Ollama目前提供三种向量转化模型,链接如下:
| Model | Parameter Size | |
|---|---|---|
| mxbai-embed-large | 334M | https://ollama.com/library/mxbai-embed-large |
| nomic-embed-text | 137M | https://ollama.com/library/nomic-embed-text |
| all-minilm | 23M | https://ollama.com/library/all-minilm |
教程推荐的nomic-embed-text是其中一种。
此外还有名为mxbai-embed-large向量转换模型,号称性能超过OpenAI的向量转换模型text-embedding-3-large,大家可以自行下载尝试。
💡 下载方式:ollama pull mxbai-embed-large 详情:https://ollama.com/library/mxbai-embed-large
对于部分同学反映Qwen 4B比较笨,可以尝试Qwen 7B模型或者Zephyr 7B模型。Zephyr 7B是在 mistral 7B 模型的基础上微调出来的一个模型。我测试之后发现中文支持还可以。
💡 Zephyr 7B 下载方式:ollama pull zephyr Zephyr 7B详情:https://ollama.com/library/zephyr
我们可以在 https://ollama.com/library 中搜索已有我们想要的模型库。以下是一些流行的模型:
| 模型 | 参数 | 尺寸 | 执行下载 |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
这里大概列出了 Llama、Mistral 以及 Gemma 我们景见的模型以及参数以及尺寸大小。由图表可以看出 Gemma 2B 模型的尺寸还是比较小的,初学者入门。
C. 手动下载模型导入 #
如果通过 ollama pull / ollama run 等方式拉取(下载)量化模型很慢,可以尝试手动下载gguf模型并导入ollama中。
导入GGUF模型
GGUF格式是一种流行的模型格式,被广泛应用于各种机器学习任务中。使用ollama框架导入GGUF模型是一个简单直接的过程,分为几个主要步骤:准备Modelfile、创建Ollama模型和运行模型。下面将逐步详细介绍每个步骤。
准备工作
在开始导入模型之前,首先需要准备一个Modelfile。Modelfile是描述如何构建模型的配置文件,它指定了模型权重、参数、提示模板等重要信息。正确设置Modelfile是成功导入模型的关键。
模型下载
我在网盘中已经上传了两个模型,zephyr 7b和qwen 7b的gguf文件。你也可以通过其他渠道(huggingface)下载gguf模型。
步骤1:编写Modelfile
创建Modelfile非常简单。首先,您需要指定模型文件的位置,如下所示:
FROM ./mistral-7b-v0.1.Q4_0.gguf
如果您的模型需要一个默认的提示模板来正确回答问题,可以在Modelfile中使用TEMPLATE指令来指定:
FROM ./mistral-7b-v0.1.Q4_0.gguf
TEMPLATE "[INST] {{ .Prompt }} [/INST]"
这样做可以确保模型在接收到输入时能够正确理解和处理。
步骤2:创建Ollama模型
拥有Modelfile后,下一步是使用以下命令创建模型:
ollama create **example** -f Modelfile
此命令会根据Modelfile中的指定,创建一个新的名为example的ollama模型实例。
步骤3:运行模型
创建模型后,可以通过ollama run命令来测试模型是否正常工作:
ollama run **example** "What is your favourite condiment?"
这个命令会将文本输入传递给模型,并输出模型的回答。通过这种方式,您可以验证模型是否已正确导入和配置。
D. AnythingLLM的API用法 #
如果你想基于AnythingLLM搭建自己的知识库服务,你可以使用AnythingLLM的API。
启动AnythingLLM之后,您可以在本地的 localhost:3001/api/docs地址找到API文档。
AnythingLLM支持完整的开发者API,可以用该API来管理、更新、或者与工作空间进行聊天。
使用AnythingLLM API与已经配置好的知识库聊天非常简单,代码如下:
curl -X 'POST' \
'http://localhost:3001/api/v1/workspace/**document**/chat' \
-H 'accept: application/json' \
-H 'Authorization: Bearer BN47Z6S-BSZM6KA-MGY1R17-W926FBZ' \
-H 'Content-Type: application/json' \
-d '{
"message": "什么是出口转内销",
"mode": "query | chat"
}'
其中**document**是Workspace的SLUG。
如果你习惯用Python,应该这样写(通过requests库):
import requests
headers = {
'accept': 'application/json',
'Authorization': 'Bearer BN47Z6S-BSZM6KA-MGY1R17-W926FBZ',
'Content-Type': 'application/json',
}
json_data = {
'message': 'What is AnythingLLM?',
'mode': 'chat',
}
response = requests.post('http://localhost:3001/api/v1/workspace/**document**/chat',\
headers=headers, json=json_data)
print(response.text)
其中**document**是Workspace的SLUG。
Python如何调用AnythingLLM API?
**使用requests库。**AnythingLLM暂时没有python库。
https://**curlconverter.com**/
这个工具网站可以直接将复制网页的curl转为python的request请求代码。
E. Docker部署Ollama和AnythingLLM #
为了方便将Ollama和AnythingLLM部署成为服务,我们需要使用Docker来运行他们。
Ollama Docker 如何安装
1.docker部署ollama
1.1.CPU模式
docker run -d -v /opt/ai/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
1.2.GPU模式(需要有NVIDIA显卡支持)
1.2.1.安装英伟达容器工具包(以Ubuntu22.04为例)
其他系统请参考:英伟达官方文档
# 1.配置apt源
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 2.更新源
sudo apt-get update
# 3.安装工具包
sudo apt-get install -y nvidia-container-toolkit
1.2.2.docker使用GPU运行ollama
docker run --gpus all -d -v /opt/ai/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
2.docker部署ollama web ui
docker run -d -p 8080:8080 -add-host=host.docker.internal:host-gateway -name ollama-webui -restart always ghcr.io/ollama-webui/ollama-webui:main
3.使用docker中的ollama下载并运行AI模型(示例为阿里通义千问4b-chat)
docker exec -it ollama ollama run qwen:4b-chat
AnythingLLM Docker 如何安装
AnythingLLM 的开发公司 Mintplex Labs 提供的官方 Docker 镜像。通过下面的指令可以启动AnythingLLM的Docker服务:
docker pull mintplexlabs/anythingllm:master
export STORAGE_LOCATION="/var/lib/anythingllm" && \
mkdir -p $STORAGE_LOCATION && \
touch "$STORAGE_LOCATION/.env" && \
docker run -d -p 3001:3001 \
-v ${STORAGE_LOCATION}:/app/server/storage \
-v ${STORAGE_LOCATION}/.env:/app/server/.env \
-e STORAGE_DIR="/app/server/storage" \
mintplexlabs/anythingllm:master
访问 http://localhost:3001 可以打开AnythingLLM的Web GUI ,操作过程和本地桌面版基本相同。
来源 https://blog.csdn.net/qq_38593436/article/details/136407171
F. 向量库管理 #
Vector Admin GUI是一个强大向量数据库管理工具,提供友好的Web图形化操作界面,用于可视化和管理 AnythingLLM 存储的向量。
安装过程涉及利用 Mintplex Labs 提供的 Docker 容器:一个用于 Vector Admin 应用程序,另一个用于 PostgreSQL 数据库,该数据库存储应用程序的配置和聊天历史记录。
git clone https://github.com/Mintplex-Labs/vector-admin.git
cd vector-admin/docker/
cp .env.example .env
我们修改 .env 文件,将服务器端口从 3001 调整为 3002,避免与 AnythingLLM 已使用的端口发生冲突。在Linux系统上,还需要为PostgreSQL连接字符串设置默认的Docker网关IP地址。
SERVER_PORT=3002
DATABASE_CONNECTION_STRING="postgresql://vectoradmin:password@127.0.0.1:5433/vdbms"
此外,我们配置 SYS_EMAIL 和 SYS_PASSWORD 变量来定义第一个 GUI 连接的凭据。
鉴于默认端口的更改,我们还在 docker-compose.yaml 和 Dockerfile 中反映了此修改。
配置完后端之后,我们将注意力转向前端安装。
cd ../frontend/
cp .env.example .env.production
在 .env.production 文件中,我们更新端口以与 Docker 网关保持一致。
GENERATE_SOURCEMAP=false
VITE_API_BASE="http://127.0.0.1:3002/api"
完成这些设置后,我们构建并启动 Docker 容器。
docker compose up -d --build vector-admin
通过 http://localhost:3002 访问 GUI 非常简单。初始连接使用 .env 文件中指定的 SYS_EMAIL 和 SYS_PASSWORD 值。仅在首次登录时需要这些凭据,以从 GUI 创建主管理员用户并开始配置该工具。
G. 什么是量化模型 #
量化是一种减小模型大小和提高推理性能的技术,它通过降低大语言模型内存储的数值精度来实现。简单来说就是把π(3.141592653….)简化成3.1415927或者3.14的过程。
不同的量化级别,代表着不同的精度。我们常用的量化精度有q4_0 、q4_1 、q5_0 、q5_1 等等 。量化模型从最低精度到最高精度排列如下:
q2_K: 提供最高压缩率的量化级别,但可能会对模型的准确度和性能产生较大影响。q3_K: 相比于q2_K,提供了更好的平衡,适用于对准确度要求较高的场景。q3_K_S: 是q3_K的一个变体,专为特定的模型结构优化。q3_K_M: 针对中等大小的模型提供了优化,介于q3_K_S和q3_K_L之间。q3_K_L: 专为大型模型设计,提供了相对较高的准确度。q4_0(推荐): 提供了一个良好的平衡点,推荐用于大多数模型。q4_1: 与q4_0相似,但略微调整了量化策略,适用于特定场景。q4_K: 适用于需要细粒度量化控制的高级用户。q4_K_S: 为小型模型提供了针对性的优化。q4_K_M: 针对中型模型进行了优化,比q4_K_S提供更广泛的适用性。q5_0: 在保持较高压缩率的同时,尽量减少对性能的影响。q5_1: 与q5_0类似,但进行了细微的调整以适应不同的模型需求。q5_K: 提供了更多的量化控制选项,适合需要精细调整的场景。q5_K_S: 专为小型模型设计,旨在在压缩率和性能之间找到最佳平衡。q5_K_M: 为中型模型量身定制,提供了优秀的压缩和性能平衡。q6_K: 介于q5_K_M和q8_0之间,为特定模型提供了更多的量化选项。q8_0: 在所有量化级别中提供了相对较低的压缩率,但保持了较好的性能和准确度。f16: 半精度浮点格式,提供了与全精度浮点相比的显著大小减少,同时基本保持了模型性能。
选择合适的量化级别需要考虑模型的大小、性能需求以及最终部署的环境。我们推荐从q4_0开始试验,并根据模型的具体表现进行调整。
H. 什么是chunk(分块)如何设置chunk #
在构建RAG这类基于LLM的应用程序中,分块(chunking)是将大块文本分解成小段的过程。当我们使用LLM embedding内容时,这是一项必要的技术,可以帮助我们优化从向量数据库被召回的内容的准确性。
当嵌入一个句子时,生成的向量集中在句子的特定含义上。当与其他句子Embedding进行比较时,自然会在这个层次上进行比较。这也意味着Embedding可能会错过在段落或文档中找到的更广泛的上下文信息。
在确定最佳分块策略时,有几个因素会对我们的选择起到至关重要的影响。以下是一些事实我们需要首先记在心里:
- 被索引内容的性质是什么? 这可能差别会很大,是处理较长的文档(如文章或书籍),还是处理较短的内容(如微博或即时消息)?答案将决定哪种模型更适合您的目标,从而决定应用哪种分块策略。
- 您使用的是哪种Embedding模型,它在多大的块大小上表现最佳?例如,sentence-transformer[1]模型在单个句子上工作得很好,但像text- embedt-ada -002[2]这样的模型在包含256或512个tokens的块上表现得更好。
- **你对用户查询的长度和复杂性有什么期望?**用户输入的问题文本是简短而具体的还是冗长而复杂的?这也直接影响到我们选择分组内容的方式,以便在嵌入查询和嵌入文本块之间有更紧密的相关性。
- 如何在您的特定应用程序中使用检索结果? 例如,它们是否用于语义搜索、问答、摘要或其他目的?例如,和你底层连接的LLM是有直接关系的,LLM的tokens限制会让你不得不考虑分块的大小。
简单来说,长文本Chunk可以设置大一点(512),短文本可以设置小一点(128)。
I. 如何设置Max Context Snippets #
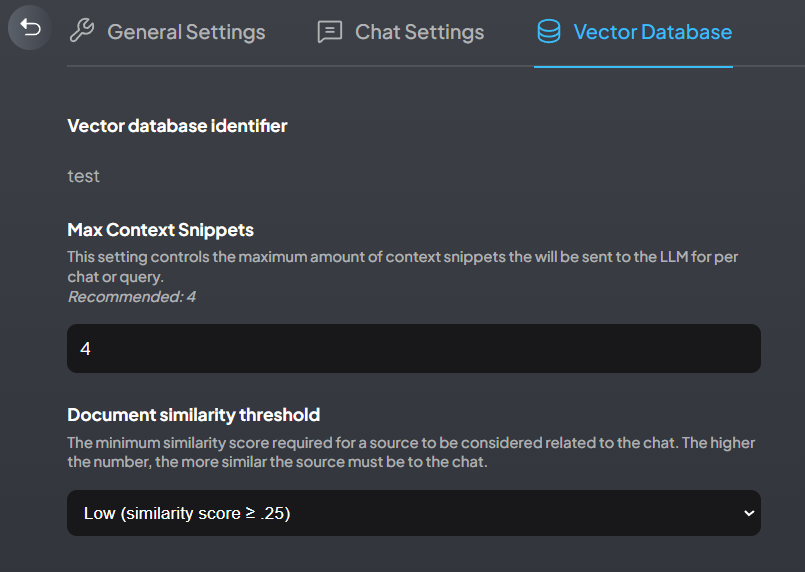
Max Context Snippets(最大参考上下文)表示大模型参考的文本切片的数量。通常这个数字越大,回答的质量就越高。
因此,你可以通过调高Max Context Snippets到8、12、16来获得质量更好的答案。
那么什么是文本切片呢,其实就是前面我们设置的embedding模型的chunk。
如果我们的chunk设置为256,Max Context Snippets设置为4(也就是默认值),那么4个切片(就是4个chunk)相当于占用4 * 256 = 1024 =1k token。我通常设置为10,那么就会占用2.5k的token。通常本地大模型能够处理的token上限是8k(同时包含问题和回答),因此我们提交给大模型的Context Snippets不能太大,太大就没有可用token计算答案了。
结论:默认的4好像对中文不友好(因为文字结构的原因),起码设到8,我通常设置10(上限为12)。
J. 知识库的内存/显存需求 #
很多朋友部确定自己的硬件是否支持运行本地大语言模型。
如果你没有nvidia的显卡(例如RTX1660、2080、3060ti这种),那么就只能考虑用CPU运行。
一种简单估算方式为:
FP16: 内存/显存占用(GB) = 模型量级 x 2
Int4: 内存/显存占用(GB) = 模型量级 x 0.75
Ollama提供的模型基本上都是Int4量化模型(少量Int5),所以如果选择内存运行的话,基本上8G可以(勉强)跑7B,16G可以(勉强)跑14B。
如果选择GPU运行的话,对系统内存和显卡显存都有要求。如果想要顺利在GPU运行本地模型的 FP16 版本,你至少需要以下的硬件配置,来保证稳定连续对话:
- ChatGLM3-6B & LLaMA-7B-Chat 等 7B模型
- 最低显存要求: 14GB
- 推荐显卡: RTX 4080
- Qwen-14B-Chat 等 14B模型
- 最低显存要求: 30GB
- 推荐显卡: V100
- Yi-34B-Chat 等 34B模型
- 最低显存要求: 69GB
- 推荐显卡: A100
- Qwen-72B-Chat 等 72B模型
- 最低显存要求: 145GB
- 推荐显卡:多卡 A100 以上
以上数据仅为估算,实际情况以 nvidia-smi 占用为准。 请注意,如果使用最低配置,仅能保证代码能够运行,但运行速度较慢,体验不佳。同时,Embedding 模型将会占用 1-2G 的显存,历史记录最多会占用数GB 的显存,因此,需要多冗余一些显存。
用显卡跑模型对电脑内存还有要求吗?
**内存要求至少应该比模型运行的显存大。**例如,运行ChatGLM3-6B FP16 模型,显存占用13G,我可以8G内存+16G显存运行吗?**不可以。**你至少要使用使用16G以上内存,否则会出现模型加载问题。
那么,跑量化模型对CPU有要求吗?
**几乎没有。**Ollama理论上支持所有带有AVX/AVX2指令集的CPU。这意味着酷睿2代(i3/i5-2xxx等)以上的CPU就可以运行Ollama驱动的大模型。
当然,我没有实测那么老的CPU,但是2015年以后出产的台式机和笔记本基本确认都是可以运行的。
K. 管理本地向量数据库 #
现在市面上的向量数据库众多,主流的向量数据库对比如下所示:
| 向量数据库 | URL | GitHub Star | Language |
|---|---|---|---|
| chroma | https://github.com/chroma-core/chroma | 7.4K | Python |
| milvus | https://github.com/milvus-io/milvus | 21.5K | Go/Python/C++ |
| pinecone | https://www.pinecone.io/ | ❌ | ❌ |
| qdrant | https://github.com/qdrant/qdrant | 11.8K | Rust |
| typesense | https://github.com/typesense/typesense | 12.9K | C++ |
| weaviate | https://github.com/weaviate/weaviate | 6.9K | Go |
我推荐初学者采用anythingllm内置的LanceDB用来管理向量数据库。但是,一旦进入实务(生产)环境,需要实现向量数据库的管理,你就需要安装独立的向量数据库了。
我推荐使用Chroma作为独立的向量数据库,安装和管理都比较简单。
Chroma介绍
Chroma的目标是帮助用户更加便捷地构建大模型应用,更加轻松的将知识(knowledge)、事实(facts)和技能(skills)等我们现实世界中的文档整合进大模型中。
Chroma提供的工具:
- 存储文档数据和它们的元数据:store embeddings and their metadata
- 嵌入:embed documents and queries
- 搜索: search embeddings
Chroma的设计优先考虑:
- 足够简单并且提升开发者效率:simplicity and developer productivity
- 搜索之上再分析:analysis on top of search
- 追求快(性能): it also happens to be very quick
Chroma安装
安装Python环境后,只需要一行指令就可以安装Chroma
pip install chromadb
-
可选包
如果你只需要使用 Chroma 的客户端功能,你可以选择安装轻量级的客户端库
chromadb-client。这个库的安装过程与 Chroma 的安装过程相同,只是包名不同。在命令行工具中输入以下命令进行安装:pip install chromadb-client
Chroma调用
这里给出一个示例:
import chromadb
chroma_client = chromadb.Client()
collection = chroma_client.create_collection(name="my_collection")
collection.add(
documents=["This is a document about engineer", "This is a document about steak"],
metadatas=[{"source": "doc1"}, {"source": "doc2"}],
ids=["id1", "id2"]
)
results = collection.query(
query_texts=["Which food is the best?"],
n_results=2
)
print(results)
Chroma一般是直接作为内存数据库使用,但是也可以进行持久化存储。
在初始化Chroma Client时,使用PersistentClient:
client = chromadb.PersistentClient(path="/Users/yourname/xxxx")
这样在运行代码后,在你指定的位置会新建一个chroma.sqlite3文件。
启动Chroma服务
打开一个CMD窗口,启动 Chroma 服务器。这可以通过运行以下命令实现:
# chroma run --path /db_path
chroma run --path d:\my_chromadb\
AnythingLLM连接Chroma
接下来,我们选择 Chroma 向量数据库,使用 URL http://127.0.0.1:8000。API handler/API key可以留空。

如何备份、管理Chroma的数据
备份比较简单,复制d:\my_chromadb\下的sqlite3数据库文件就可以了。管理的话可以用HeidiSQL进行简单管理。向量层面的管理可以采用Vector Admin工具或者。
更多复杂的Chroma操作请参考: https://cloud.tencent.com/developer/article/2407496
L. 注册在线向量数据 #
Milvus 是一款开源向量数据库,提供在线版本的向量数据库服务,在线服务的名称叫做Zilliz。可以通过下面这个地址注册他的免费版本,免费版最多支持两个数据集合(Collection)。
https://zilliz.com/zilliz-cloud-free-tier
注册完成后,你需要先创建一个cluster(集群)。
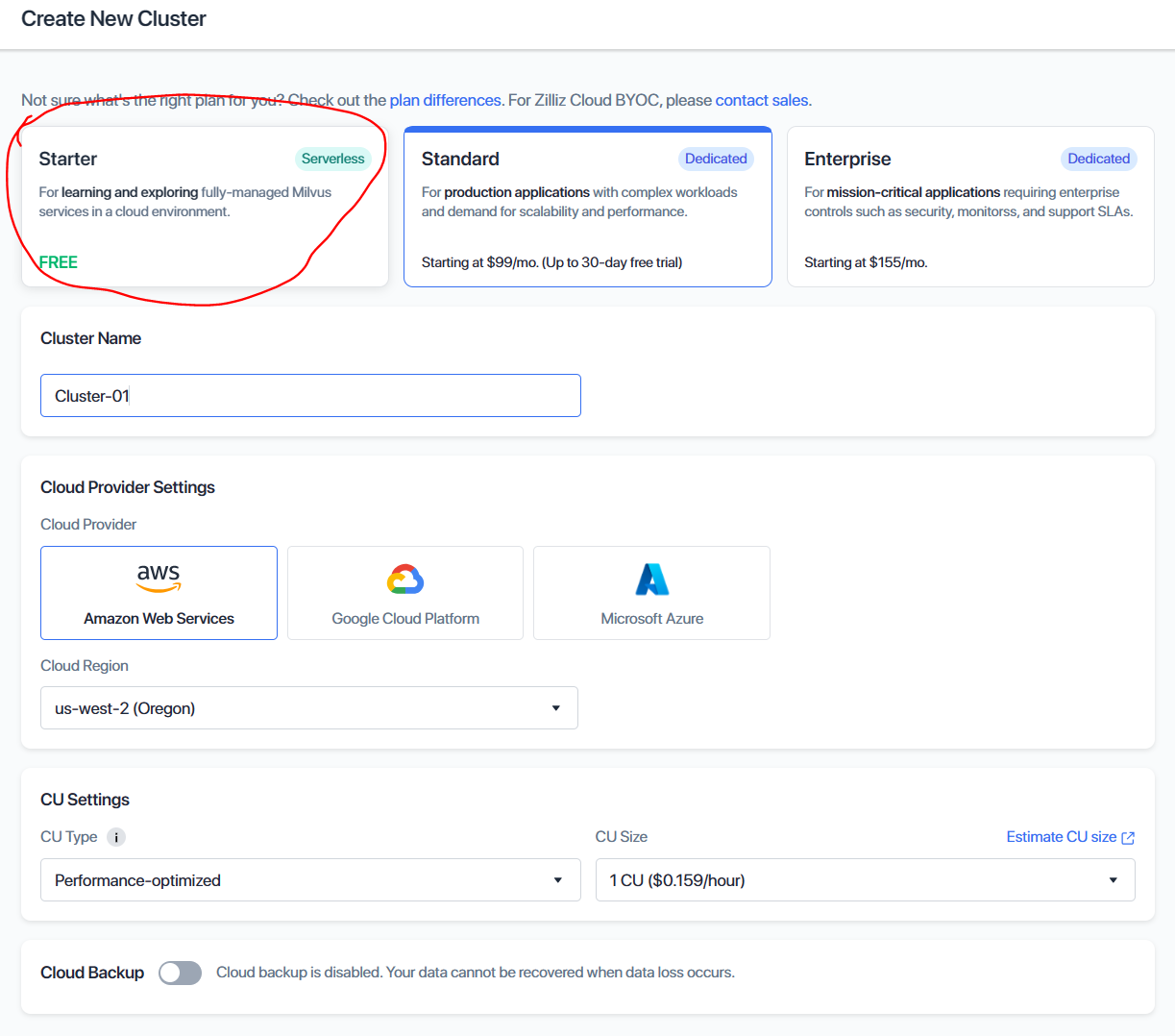
免费账户没有太多可选项,按照默认创建即可。
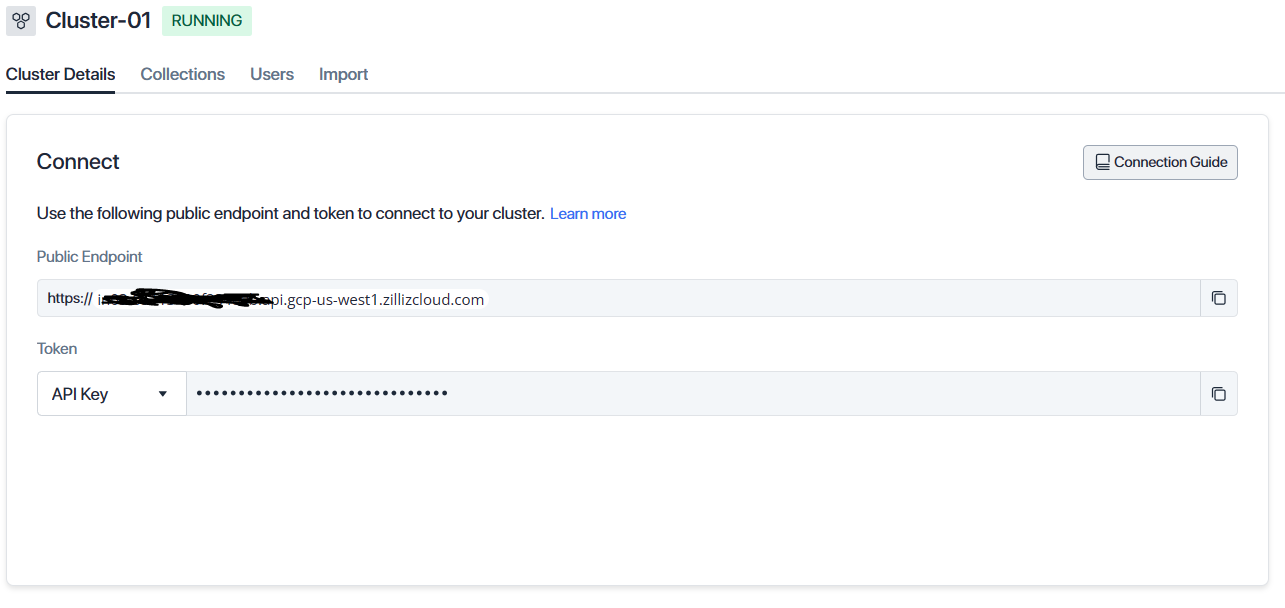
复制上面的Endpoint URL和API key到AnythingLLM中就可以使用在线的向量数据库了。
提示:更换向量数据库后,需要对文档进行重新向量化!
Q&A 常见错误汇总 #
- AnythingLLM 无法连接 Ollama
提问时,AnythingLLM报错,提示如下:
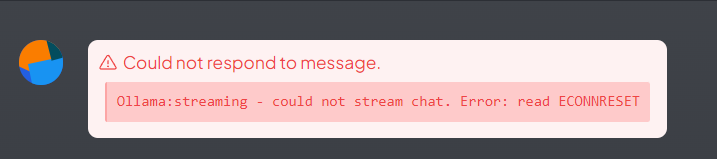
原因:Ollama崩了,或者内存不足。
解决方案:
- 在CMD窗口运行
ollama serve,再试 - 重启,再试
- 更新Ollama和AnythingLLM到最新版本,再试
- 重新下载Ollama模型,再试
出现这个问题,一般是由于小马拉大车(小内存跑大量级模型)造成的,再加上Ollama目前处于Preview状态,并不是很稳。
2. AnythingLLM 安装完成后打不开(不显示主界面)
首先尝试重启。AnythingLLM 界面看起来很简单,但其实后面跑了一堆服务,只要有一个衔接不上,就很容易崩。
如果重启不能解决,需要重新安装官方(非精简的)Windows系统。如果你安装的就是官方系统,也可以尝试进行系统还原。
新安装的系统可以保证AnythingLLM的服务不与其他已经存在的服务冲突。
- 文档Embeding失败
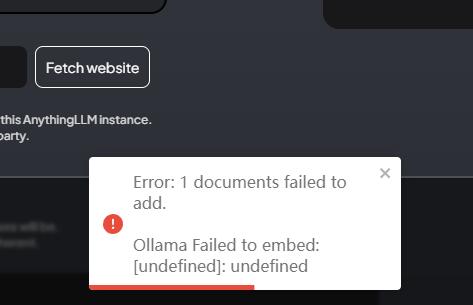
原因:格式问题、Ollama崩了、模型崩了、向量数据库崩了
解决方案
-
尝试转换文档的格式,例如将txt复制到word中,再次添加。或者将word导出为pdf,再次添加。AnythingLLM对utf-8 无bom的txt文件兼容性最佳,其他的doc、xls、ppt等格式,由于office版本众多,也可能出现兼容性问题,建议转存为最新版本的office文档格式,再重新尝试。
-
另外,ollama管理的向量转换模型(nomic-embed-text)也可能出现错误,可以尝试删除向量转换模型后,重新通过ollama下载。
# 先删除原模型 ollama rm nomic-embed-text # 再重新下载向量模型 ollama pull nomic-embed-text -
本地的lanceDB损坏或崩溃,先删除所有向量化文档,重试;如果不行,删除workspace,重试;还不行,卸载anythingllm并重新安装。对于生产环境,建议安装独立的向量数据库,例如Chroma,或者使用在线数据库,例如Pinecone。
-
你在使用过程中,调整了embedding的chunk大小,也可能导致后面添加文档失败,可以删除workspace后,重新创建并添加文档。
-
AI答非所问
首先,修改chunk大小,从512开始往小改,最小为128(太小了反而性能不好)。然后重新添加文档并进行向量化(记得删除之前添加的文档),最后重试问答效果。
其次,修改Max Context Snippets参数(默认为4),根据你的电脑性能,调整为8、12等值(我经常设为10)
最后,尝试量级更大的模型,例如从qwen 4b替换到qwen 7b或者更大的模型;尝试更新的模型,例如尝试zyphyr、gemma等新模型
- 为什么总是给我飙英文
很多朋友采用中文提问,却常常得到英文回答。这是因为大模型的训练材料中英文居多,开发者又没有优化它采用中文回答导致的。通常出现在国外发布的大模型上,但是偶尔也出现在国内的大模型中。
你可以重新问一遍,并在问题后面追加“用中文回答我”,一般就能让大模型改回使用中文。
如果经常性的出现英文答案,也可以尝试在Prompt中添加“Always reply the answer in Chinese language.”
- 回答还行,但是点开引用(Citations)显示的乱码

你上传的文档(doc、txt等)的编码(通常是gb2312/gbk)AI可以读懂,但是anythingllm的显示界面不认识这个编码。可以不用管。如果很介意,将文档另存为utf-8的txt格式,重新上传即可。