无需显卡 利用chatglm3-6b来搭建自己的本地大源模型
怎么样搭建一个属于自己的AI大语言模型应用呢?今天我们就利用chatglm3-6b来搭建自己的本地大源模型。
· 2 min read
搭建本地的AI大语言模型 #
更多AIGC教程,访问UP「码钉泥」的B站 https://space.bilibili.com/650927704/
ChatGPT虽好,确有诸多限制。需要魔法上网、需要境外手机号注册。当用户过多的时候,还需要耐心排队才能够使用。当你希望进行一些自动化的API操作时,你还需要准备一张境外银行卡进行支付,才能获得使用API的权限。
那么,怎么样才能够搭建一个完全属于自己的不用受限且免费的本地大语言模型呢?
请看下面的公式:
ChatGLM3 + ChatBox + Python + 中档性能以上的计算机 = 私有大语言模型
今天我们就来帮助大家实现这个看似不可能完成的任务。放心吧,ChatGLM3、ChatBox、Python都是免费软件。
前置 #
如果你没有Python编程的任何经验,你可以考虑看一看我的Python五分钟入门教程。当然了,这并不是必须的。
软件环境 #
本教程仅适用于Windows开发环境。请使用Windows 10 / 11 和 Python 3.8 以上版本进行配置。笔者使用的是 Win11 22H2 Pro 和 Python 3.8 环境。
第一步 语言模型 #
关于ChatGLM3模型 #
我们需要用到ChatGLM3模型,关于ChatGLM3模型是何方神圣,就让它自己来介绍一下吧。

ChatGLM3-6B 是一个人工智能助手,由清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型 GLM3-6B 开发而成。该助手基于大型语言模型,可以针对用户的问题和要求提供适当的答复和支持。ChatGLM3-6B 的能力涵盖了对话、摘要、翻译、问答等方面,适用于多种场景。该助手还具有自然语言处理和机器学习技术,能够不断学习和优化自己的回答能力。
根据笔者的实际测试,发现ChatGLM3-6B的中文问答能力强于依托LLaMA/LLaMA2训练的Alpaca-6B / Vicuna-6B / Alpaca-6B-Chinese等开源语言模型。作为简单的办公小助理,执行百科查询、公式编写、外语翻译等应用,的确可以起到提高工作效率的作用。
获取ChatGLM3 #
ChatGLM3是一款开源模型,你可以通过下面的地址去下载它们。
| Seq Length | Download | |
|---|---|---|
| ChatGLM3-6B | 8k | https://huggingface.co/THUDM/chatglm3-6b |
| ChatGLM3-6B-Base | 8k | https://huggingface.co/THUDM/chatglm3-6b-base |
| ChatGLM3-6B-32K | 32k | https://huggingface.co/THUDM/chatglm3-6b-32k |
不过上面三个模型都不是今天的主角。今天我们需要下载一个经过量化处理后的ChatGLM3-6b模型。
什么是模型量化 #
量化处理可以通过将模型参数和模型本身转化为数字形式来减小模型的存储空间。在传统的模型训练中,模型参数和模型本身通常被存储为二进制文件或文本文件,这些文件通常占用较大的存储空间。而量化处理可以将这些参数和模型转换为更小的数字形式,例如浮点数或整数,从而减小文件的存储空间。此外,量化处理还可以将模型中的某些参数进行压缩或剪裁,以进一步减小模型的存储空间。这些措施可以有效地提高模型的存储效率,降低模型的部署成本,并加快模型的训练和部署速度。
使用量化模型的另外一个好处是,你可以单独使用CPU运行这些模型,而不再需要显卡,并且占用更小的内存。因为量化过程将浮点数据(更适合显卡运算)转换成了整形数据(更适合CPU运行)。ChatGLM-6B未量化之前需要占用13G的显存或者32G的内存才能运行;而进行量化之后,可以在8G内存的主机上运行。
如何转化量化模型? #
量化运行库通常会提供进行模型量化的工具。我们将使用https://github.com/li-plus/chatglm.cpp来运行ChatGLM3-6B模型,它为我们提供了转换工具。使用 convert.py 将 ChatGLM-6B模型 转换为量化 GGML 格式。例如,将 fp16 原始模型转换为 q4_0 (量化 int4)GGML 模型,可以运行:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o chatglm-ggml.bin
前提是你已经下载了完整地ChatGLM-6B模型(大约13G)。或者,我们也可以直接下载已经转化好的ChatGLM-6B量化模型。
如何下载量化模型? #
- 你可以访问这个地址下载:
https://www.modelscope.cn/models/tiansz/chatglm3-6b-ggml/files
下载下面这个文件
chatglm3-ggml.bin
-
或者 点击这里 直接下载
-
或者通过 git 克隆这个repo获得量化模型
git clone https://www.modelscope.cn/tiansz/chatglm3-6b-ggml.git
最后你将获得一个 3.27G 大小的 chatglm3-ggml.bin 文件。将它存储到你的工作目录下。
第二步 配置API环境 #
接下来,我们将进行API运行环境的配置。你需要在自己的电脑上安装Python 3.8以上的版本。我推荐安装Python 3.10.6(许多AI应用都推荐使用这个版本),或更新的Python 3.10.x运行环境。当然,根据笔者实际使用体验,Python 3.8(截至2023年12月仍在维护的最低版本Python3)跑起来也没有太大问题。
创建虚拟环境 #
我们需要为ChatGLM3-6b创建一个虚拟运行环境,以避免不同的Python应用之间发生干扰。
首先安装virtualenv(这是一款古老的虚拟环境创建工具):
pip install virtualenv
然后创建一个名为local_chat的虚拟环境:
virtualenv local_chat
现在local_chat目录就是你的工作环境,你可以将你下载好的chatglm3-ggml.bin文件放到这个目录下面。
接下来让我们激活这个虚拟环境并安装必要的运行库。打开一个cmd窗口,并且切换到你的工作目录。
cd D:/local_chat
./Scripts/activate.bat
现在你可以看到命令行窗口的提示符前面出现了一个括号,括号内显示(local_chat)。这意味着你已经激活了虚拟环境。虚拟环境对于Windows的目录操作没有任何影响。它只针对Python的运行环境有效。当你激活了虚拟环境后,无论你在任何目录下进行Python相关的操作,你调用的都是虚拟环境内的Python和pip运行库管理工具。
现在我们需要安装ChatGLM3-6b运行所需要的一些Python库。
请访问下面这个链接,下载与你的Python版本相同的whl文件。
https://github.com/li-plus/chatglm.cpp/releases/tag/v0.3.0
或者直接点击下面的下载链接也可以。
chatglm_cpp-0.3.0-cp38-cp38-win_amd64.whl
chatglm_cpp-0.3.0-cp39-cp39-win_amd64.whl
chatglm_cpp-0.3.0-cp310-cp310-win_amd64.whl
chatglm_cpp-0.3.0-cp311-cp311-win_amd64.whl
chatglm_cpp-0.3.0-cp312-cp312-win_amd64.whl
同样下载完成后,请把这个文件放到你的工作目录。执行下面的指令,通过whl文件离线安装运行库。
(lcoal_chat) D:/local_chat pip install chatglm_cpp-0.3.0-cp310-cp310-win_amd64.whl
我推荐你采用上面的方法。当然你也可以跳过下载whl文件,尝试使用下面的指令在线安装。
pip install chatglm_cpp
你很可能发现安装失败。因为本地编译需要安装Visual studio 2023 community版本。
当你安装完成chatglm_cpp的基础运行库后,我们还需要安装其他辅助库。
pip install 'chatglm-cpp[api]'
因为你之前已经进行了chatglm-cpp的本地安装,安装程序会自动跳过它,并继续安装其他的辅助库。这些辅助库将帮助我们在本地启动一个API服务器。
如果你的安装过程非常漫长,甚至出现失败,你可以尝试搜索“pip清华源”或“pip中科大源”,并根据网上的提示修改你的pip下载源。然后重新运行上面的辅助库安装指令。
什么是API服务器?
没关系,你不用准确理解什么是API服务器。你只需要知道它将会调用chatglm3-ggml.bin文件,并解答我们提出的任何问题。
创建一个名为API_server.bat的文件,复制下面的内容到这个文件内,并保存至工作环境。
set MODEL=%~dp0chatglm3-ggml.bin
call %~dp0/Scripts/activate.bat
cd %~dp0
uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000
双击 API_server.bat 文件,如果出现下面图片中的界面就说明你的API服务器已经正常开始工作。

如果你看见命令行窗口闪现又关闭。那么很可能是因为你的目录结构与我设置的不同。请参考我的目录结构重新放置你的文件,然后重试启动API服务器。
第三步桌面客户端 #
现在你已经拥有一个正在运行ChatGLM3-6b API服务器。我们打开一个命令行窗口,简单测试一下吧。
curl http://127.0.0.1:8000/v1/models
几秒钟后,你就能从屏幕上读取回复(返回可用的模型列表)。
{"object":"list","data":[{"id":"gpt-3.5-turbo","object":"model","owned_by":"owner","permission":[]}]}
很好,这说明我们的系统运行正常。但是这样不太方便,我们需要下载一个桌面客户端来进行提问和查看回答。
我推荐你们使用chat box这个工具。它的界面如下图所示。
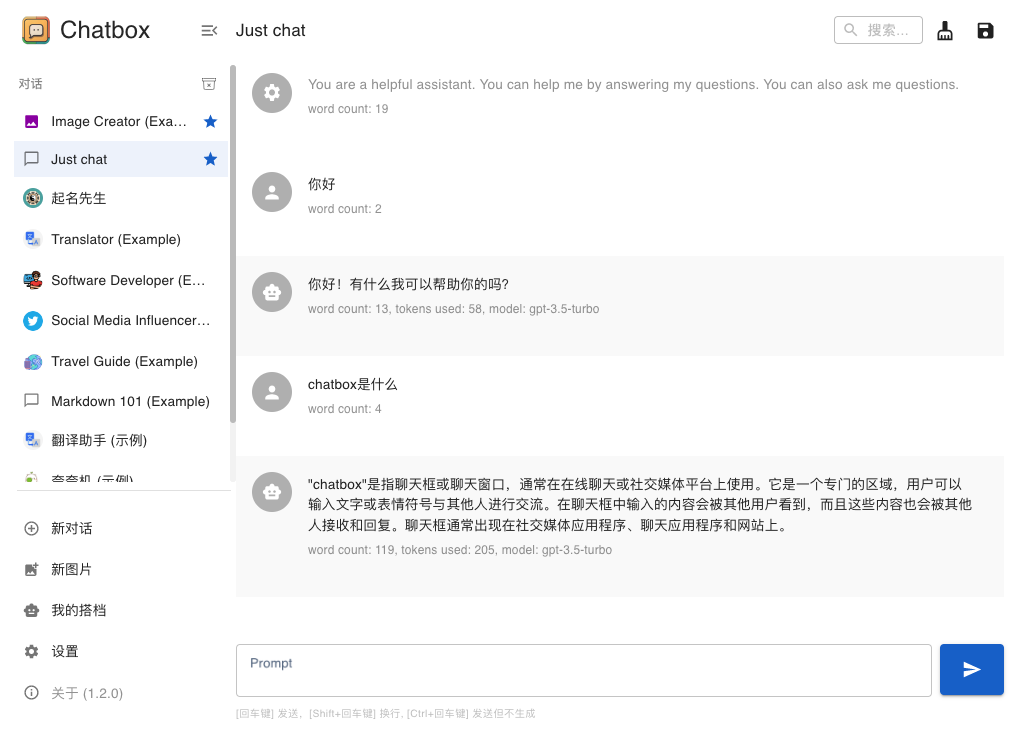
你可以通过下面这个地址。
完成简单的安装后,我们需要配置Checkbox的API服务器。
- 点击设置。在模型选项卡中,将AI模型提供方更改为OpenAI API。
- OpenAI API密钥留空。
- Api域名填写:
http://127.0.0.1:8000
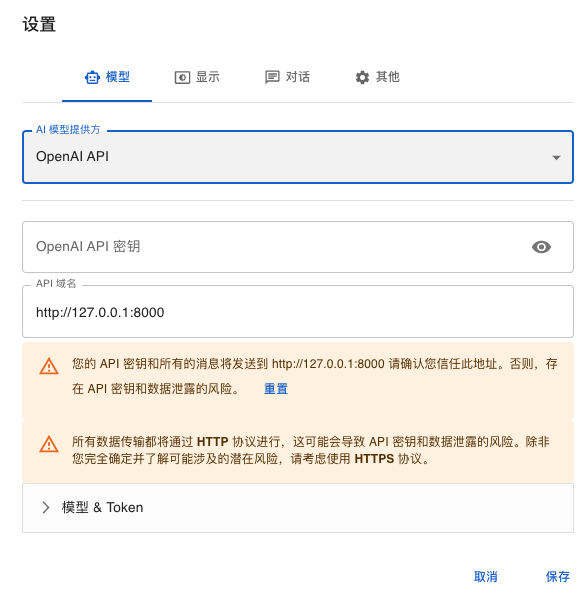
保存以上配置。点击chatbox左侧的just chat标签,尝试与ChatGLM3-6B模型进行对话。根据你的计算机的性能,通常需要等待几秒到几十秒才能获得回答。
你也可以尝试chatbox提供的预制人设,这些人设可以帮助你撰写小红书文案、提供人生格言或进行外语翻译。
总结 #
笔者测试,英特尔i5 6代处理器、8G内存的笔记本电脑回答一般问题的耗时大约6090秒。英特尔i77代处理器,16G内存的台式机回答一般问题耗时大约1020秒。英特尔i5 12代处理器,16G内存的笔记本电脑回答一般问题的耗时大约10~30秒。基本上最近几年生产的主流笔记本或台式机,都可以按照上面的方法运行本地大语言模型。你也可以尝试测试更老的CPU和更小的内存组合,欢迎和笔者分享你的测试结果。
今天我们通过简单的配置实现了本地运行ChatGLM3-6B大语言模型。下一篇,嗯我们尝试使用本地大元模型处理更加复杂的任务:自动撰写文案。
更新:一键启动懒人包 #
https://www.123pan.com/s/5cWiVv-WCDC.html 提取码:leai
下载 懒人包/ChatGLM3_cpp.7z 后解压到本地目录,然后下载 量化模型/chatglm3-ggml.bin,
放在ChatGLM3_cpp目录下。双击“一键运行.bat”就可以启动服务端了
请注意,你仍然需要配置Chatbox等LLM聊天程序中配置端口(http://127.0.0.1:8000),才能实现本地大语言模型对话。